
こんにちは。
今回はParselmouthとk-meansクラスタリングを使った母音推定を起こったので、紹介していきます。
忙しい方のために、私のGitを紹介しますので、お急ぎの方はコードを眺める方が早いかと思います。

なんでそんなことしたの?(背景・動機)
とある依頼で、「音声データを読み込むことで、自動で母音に合わせた口パク動画を作れるようにできないか?」という相談を受けました。
音声データによる解析は、過去ブログで自分の息子(当時2か月)の声を使って検討したことがあります。
余談ですが、はてなブログはそのままURLコピペすると綺麗に埋め込みカードができていいですね!
QiitaとかGithubでも、WordPressでは埋め込みカードを作るためにはプラグインが必要だったりします。
Githubみたいな有名どころはデフォルトでコピペOKにしてほしいですね・・。
話を戻すと、音声データに関する知識を深める良いチャンスだと思い、検討を始めたのがきっかけになります。
フォルマント分析
では母音はどのようにして抽出・判定すれば良いでしょう?
そのひとつの方法に「フォルマント分析」というものがあります。
以下の記事を参考にしました。

ざっくり要点をまとめると、
「第一フォルマントと第二フォルマントを使えば母音の領域を推定できるよ」
なるほど、さっそく真似てみよう、と思ったのですが、結構色んな下準備が多そうでめんどくさそう。。
もっと簡単に、音声データに対してフォルマント分析ができるのかできないのかを把握したい!
そんな便利なライブラリはないだろうか・・。
ありました。
それが「Parselmouth」です。
Parselmouth
Parselmouthは「Praat」という音声認識ライブラリをPythonで呼び出す、いわゆるラッパー関数になります。

音声解析のPythonライブラリといえばlibrosaが有名ですが、今回はParselmouthを使ってみます。
librosaにもフォルマント分析は可能ですが、今回はとにかく楽に最速で検証することを目的とするためParselmouthを使用します。
VOICEVOXを使ってサンプル音声を作成
解析する音声はVOICEVOXを使って作成します。

最近流行りの無料で使えるテキスト読み上げソフトウェアです。
「あいうえお」が正しく推定できるかを確認したいだけなので、いくつかのキャラクターに「あいうえお」としゃべってもらう音声を作成したいと思います。
ダウンロードやインストールは割愛しますが、良さそうな記事を貼っておきます。

どの記事を見てもGPUタイプをインストールしていますが、おそらく短文で作成する方はCPUタイプで良いと思います。
GPU使う方が処理速度的に有利なんでしょうが、光熱費やPCが熱くなるの嫌な人はCPUタイプがおすすめです。
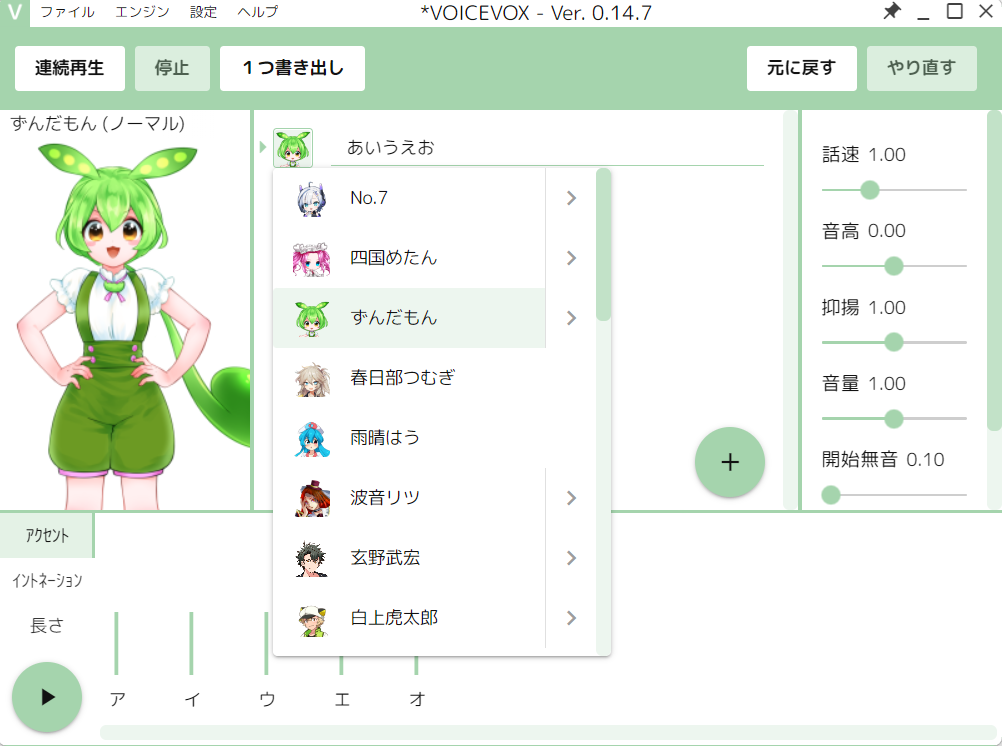
で、ひととおり設定が終わって立ち上げると以下のような画面になります。
今回は「玄野武宏」「ずんだもん」「No.7」で実験します。
キャラクターの名前の横に「>」があるところをクリックすると、微妙にタイプを変更できます。
今回は全員「ノーマル」タイプで実験します。
キャラクターを選択後、アイコンの横にある長いテキストチャット欄みたいなところをクリックすると、以下のような画面に切り替わります。
では、テキストチャット欄に「あいうえお」と入力しましょう。
すると下にイントネーションが表示されます。
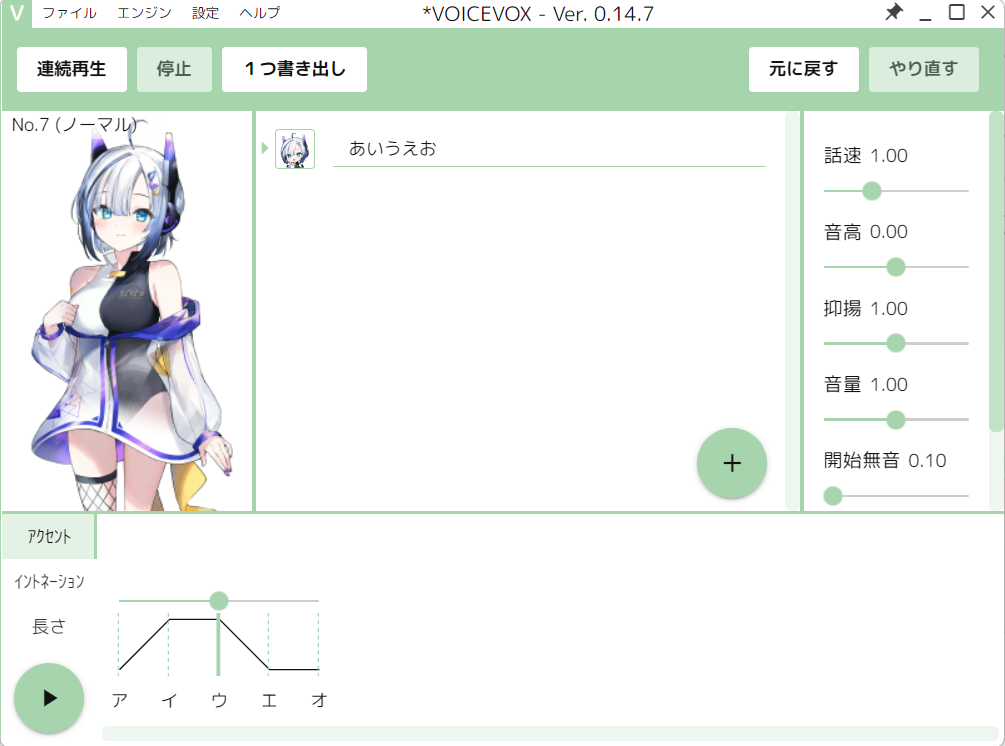
ここで左下の再生ボタンを押すと「あいうえお」としゃべってくれますので、確認します。
今回は純粋な「あいうえお」が確認したいので、イントネーションをなくします。
それぞれの間をクリックしていきましょう。
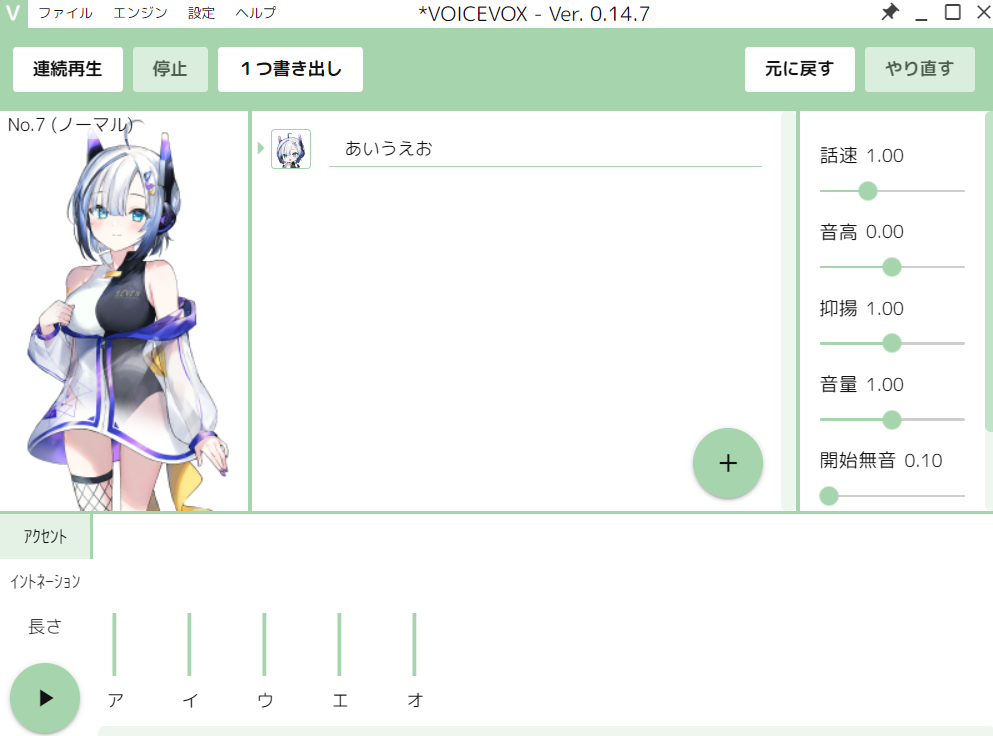
イントネーションがなくなった「あいうえお」も、再生ボタンを押して確認しましょう。
確認できましたら、「1つ書き出し」ボタンを押せば、wavファイルを生成できます。
この要領で他のキャラクターも作成しましょう。
このままキャラクターのアイコンをクリックすると、同じ「あいうえお」のまま変更できます。
以上でサンプル音声の作成は完了です。
k-meansクラスタリング(教師なし学習)
今回の音声は「あいうえお」と正解が分かっています。
しかし、現実問題として音声の母音の正解は文字おこしツールなどを使わなければわからないと思います。
(文字おこしツールでも間違ったり、起こせなかったりする場合もありますし)
で、そのような正解がわからない問題を機械学習を使って推定しようとするようなとき、「教師なし学習」が想定されます。
今回は母音のラベリングができないことを想定して、k-meansクラスタリングを使用します。

すごくざっくり説明すると、データの固まりごとに重心点を算出し、その距離から近い者同士でグループ分けするような方法です。
なのでこれにより、データの規則性からラベル付けを自動で行ってくれるというわけです。
そしてこのアルゴリズムも自分で一から作ると大変ですが、オープンソースの力でなんと無料で簡単に使うことが出来ます。(本当に技術者達に感謝!)
そのPythonライブラリがscikit-learnです。
説明するよりコードで紹介した方がわかりやすいので、また後程紹介します。
必要なPythonライブラリのインストール
では次に必要なPythonライブラリのインストールをしていきましょう。
私が動かしたPythonライブラリと、バージョンは以下になります。
- matplotlib=3.7.2
- praat-parselmouth=0.4.3
- pandas=2.0.3
- scikit-learn=1.3.0
「pip install」の後に続けて、上記のものを半角スペース空けて入力していってください。
仮想環境やpip installについては過去記事でも触れていますので、こちらも参照ください。
Pythonコード作成
では実装していきます。
トップで紹介したGitの「lpc.py」の内容になりますが、コードは以下です。
import parselmouth
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
# 音声を読み込む
wav_name = "aiueo_zunda.wav"
snd = parselmouth.Sound(wav_name)
# フォルマント分析
formants_burg = snd.to_formant_burg(
max_number_of_formants=5.0, maximum_formant=5500.0, window_length=0.025, pre_emphasis_from=50.0
)
# 各時刻における第1~第4フォルマントを取得する
formants = []
for t in formants_burg.xs():
tmp = []
for num in range(1, 5):
tmp.append(formants_burg.get_value_at_time(formant_number=num, time=t, unit="HERTZ") / 1000)
formants.append(tmp)
df = pd.DataFrame(formants, columns=["1", "2", "3", "4"], index=formants_burg.xs())
df = df[["1", "2"]]
df = df.dropna(how="any")
df = df.reset_index()
# k-meansクラスタリングを実行
n_clusters = 5
kmeans = KMeans(n_clusters=n_clusters, random_state=0, n_init="auto")
kmeans.fit(df)
labels = kmeans.labels_
centers = kmeans.cluster_centers_
result_df = pd.concat([df, pd.DataFrame(labels, columns=["kmeans_result"])], axis=1)
colors = ["red", "blue", "green", "purple", "orange", "black"]
fig = plt.figure(figsize=(10, 8))
ax1 = fig.add_subplot(121)
ax2 = fig.add_subplot(122)
print(result_df.head())
for i in range(n_clusters):
ax1.scatter(result_df["1"][labels == i], result_df["2"][labels == i], label=i, color=colors[i], alpha=0.3)
ax2.scatter(result_df["index"], result_df["kmeans_result"])
ax1.set_title("k-means", size=14)
ax1.legend()
ax1.set_xlabel("folmant1", size=12)
ax1.set_ylabel("folmant2", size=12)
ax2.set_title("time-chart", size=14)
ax2.set_xlabel("time", size=12)
ax2.set_ylabel("cluster", size=12)
plt.savefig(f"output/{wav_name.split('.', 1)[0]}.png")
plt.show()解説していきます。
import parselmouth
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
# 音声を読み込む
wav_name = "aiueo_zunda.wav"
snd = parselmouth.Sound(wav_name)
# フォルマント分析
formants_burg = snd.to_formant_burg(
max_number_of_formants=5.0, maximum_formant=5500.0, window_length=0.025, pre_emphasis_from=50.0
)import文で必要なライブラリを設定します。
wav_nameのところが先ほど作成したサンプル音声データのファイル名です。
なので、先ほど作成したサンプル音声データと同じ階層でlpc.pyファイルは作成しましょう。(遅
階層のイメージとしてはGitを参照ください。
snd = parselmouth.Sound(wav_name)で音声データの読み込みが完了です。
フォルマント分析も、読み込んだparselmouthオブジェクト(snd)にメソッドでto_formant_burgを呼び出せばOKです。簡単ですね!
引数はとりあえず公式デフォルトのままで問題ないと思います。
# 各時刻における第1~第4フォルマントを取得する
formants = []
for t in formants_burg.xs():
tmp = []
for num in range(1, 5):
tmp.append(formants_burg.get_value_at_time(formant_number=num, time=t, unit="HERTZ") / 1000)
formants.append(tmp)
df = pd.DataFrame(formants, columns=["1", "2", "3", "4"], index=formants_burg.xs())
df = df[["1", "2"]]
df = df.dropna(how="any")
df = df.reset_index()
第1~4フォルマントまでを抽出するコードです。
途中1000で割ってるのは、HzをkHzに単位換算しています。
出力が終わったらPandasのデータフレームに入れて、再度第1、第2フォルマントだけに絞ります。
後は万が一判定できなくて空白値(または無効値)が入った行はdropnaで取り除く処理を入れています。
処理が終わればreset_indexでindexを整えます。
# k-meansクラスタリングを実行
n_clusters = 5
kmeans = KMeans(n_clusters=n_clusters, random_state=0, n_init="auto")
kmeans.fit(df)
labels = kmeans.labels_
centers = kmeans.cluster_centers_
result_df = pd.concat([df, pd.DataFrame(labels, columns=["kmeans_result"])], axis=1)ここでk-means法を使います。
n_clustersは名前の通りクラスタリングする数を指定します。
今回は母音で推定したいため「a, i, u, e, o」の5つとします。
後はscikit-learnでKMeansメソッドを呼び、引数を渡します。
result_dfは元々のdataframeにクラスタリングした結果のラベルを結合しています。
colors = ["red", "blue", "green", "purple", "orange", "black"]
fig = plt.figure(figsize=(10, 8))
ax1 = fig.add_subplot(121)
ax2 = fig.add_subplot(122)
print(result_df.head())
for i in range(n_clusters):
ax1.scatter(result_df["1"][labels == i], result_df["2"][labels == i], label=i, color=colors[i], alpha=0.3)
ax2.scatter(result_df["index"], result_df["kmeans_result"])
ax1.set_title("k-means", size=14)
ax1.legend()
ax1.set_xlabel("folmant1", size=12)
ax1.set_ylabel("folmant2", size=12)
ax2.set_title("time-chart", size=14)
ax2.set_xlabel("time", size=12)
ax2.set_ylabel("cluster", size=12)
plt.savefig(f"output/{wav_name.split('.', 1)[0]}.png")
plt.show()後はクラスタリングした結果をラベリング毎に色分けした散布図を使って可視化しています。
以上が実装したコードの内容になります。
続いて、一番大事な結果の確認です。
実験結果
まずは「ずんだもん」の結果からです。
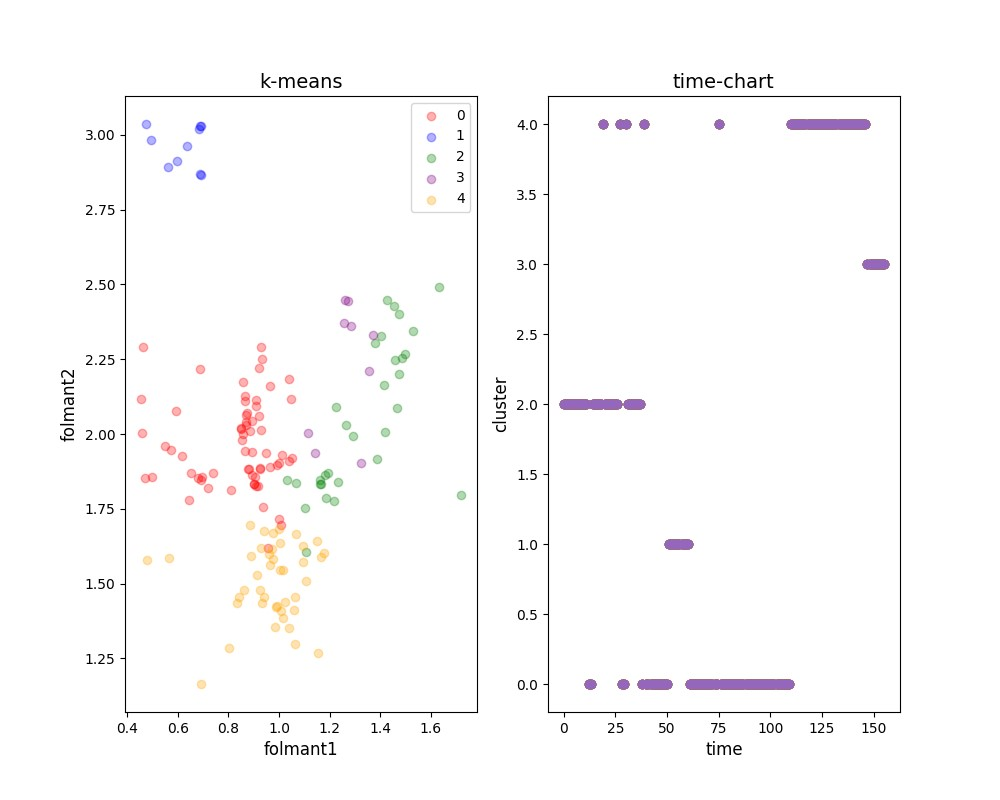
グラフの見方から解説します。
まず左のグラフは横軸に第一フォルマントの値、縦軸に第二フォルマントの値となっております。
0~4までクラスタリングによるラベリングされており、ラベル毎に色分けしています。
これらのラベルが「a, i, u, e, o」のいずれかを示していると狙い通りというわけです。
で、それが正しく分けられたかどうかを見るのが、右のグラフになります。
右のグラフは横軸に時間軸、縦軸にラベリングされた値となっております。
今回の音声は「あいうえお」というのがあらかじめわかっているのため、かならず「a, i, u, e, o」になっています。
つまり、0~4までのラベルがどの母音として分けたかを可視化しているということです。
ずんだもんの例でいくと、(やや紛らわしい点もありますが、固まってる順番で判定します。)
- a = 2
- i = 1
- u = 0
- e = 4
- o = 3
ここで↑のQiitaリンク先より、一般的なフォルマント分析のグラフを参照します。
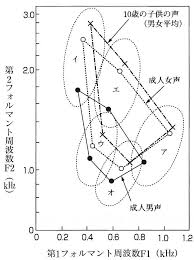
このグラフとずんだもんのグラフを比較すると、「a, i, u」は概ね似たようなポジショニングになっていることがわかります。
「e, o」が逆になっていますね。
なぜずんだもんの音声は逆になってしまったのか、気になるところですね。
一旦深堀りはせず、他のキャラクターも見ていきましょう。
続いて「玄野武宏」です。
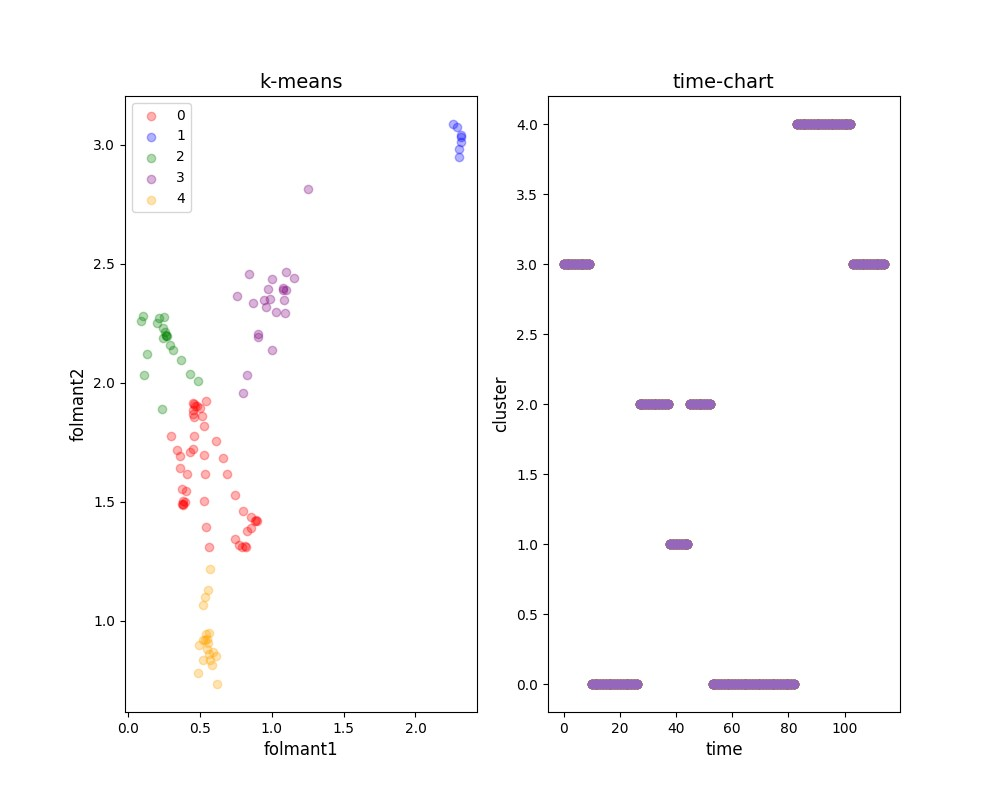
- a = 3
- i = 0
- u = 2
- e = 4
- o = 3(?)
おそらく「a, o」はクラスタリング上近すぎて判別できなかったんでしょう。
特に外れ値的に1というラベリングが出来てしまった以上、くっついてしまうのはやむを得ない気がします。
ずんだもんと比べて、「i」と「u」が逆になっているところが特徴的ですね。
一方で「e」と「o」が一般的な音声のプロットと比べて逆なのは、ずんだもんの時と同じ特徴です。
面白いですね。VoiceVoxの特徴が見えてきたようにもみえますね。
最後に「No.7」です。果てしてどのような結果となっているでしょう。
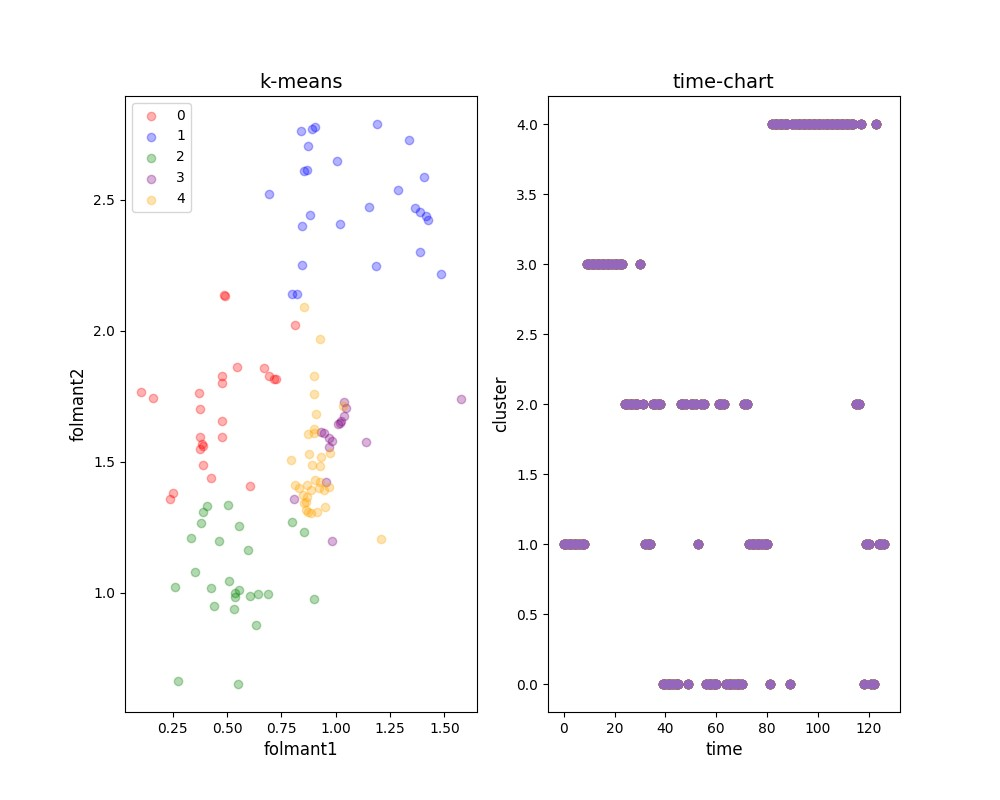
- a = 1
- i = 3
- u = 2
- e = 0
- o = 4
3キャラクター中、最も推定が難しいように見えます。
No.7はこれまでのキャラクターとも一般の音声分類とも違う構造をしているようです。
そもそもk-meansによる分類において、かなり不安定な推定(右のグラフが時系列で途切れ途切れなところ)をしていることから、No.7の音声は「あまり特徴がない」可能性を示唆しているようにも見えます。
結論
結論として
- 一般的な母音推定の領域に対して、VoiceVoxは必ずしも同様の傾向とは限らない
- キャラクターによっても推定領域が異なる
- k-meansクラスタリングによる推定も、必ずしも母音で分割できるとは限らない
以上を総合的に考えて、母音に応じた口パク動画を作ることは、精度的に難しいことがわかりました。
単純な「あいうえお」で検証してみましたが、もう少し長い文章で試せば、綺麗に分けられるかもしれませんね。
また子音との組み合わせ次第では更に推定は難しくなるかもしれません。
子音も考慮した口パクを作るとなると、更に解析技術を考える必要があると思います。
いかがだったでしょうか?
今回は様々な分野の技術を色々組み合わせて実験してみました。
音声解析面白いですね。
AIの技術も活用して、自動化ツールを作るのも不可能ではないと思います。
皆さんも良かったら試しにコードを作成してみて、いろんな音声でフォルマント分析を試してみてください。
ここまでご覧いただきありがとうございました!
