
こんにちは。
最近ローカルLLMツールのOllamaにハマっております。
先月、Gemini APIが無料枠出たから、これ使いましょうって話の記事出しましたが、それももう使わずにローカルLLMでEnjoyしてます。

少し前までは、ローカルLLMというと、そのままでは正直使い物にならない性能でした。
おまけに実装も大変で、GPUなどのコストも高いため、大企業や研究機関がファインチューニングに明け暮れてるというイメージでした。(ちょっと偏見入ってます)
しかし!Ollamaの存在を知り使っていくにつれ、その考えを改めました!
まずGPUなくても動きます。
量子化という技術のおかげでモデルのサイズも4~8GB程度なので、PCのメモリが16GB以上あればよっぽど問題なく動きます。
インストールもめちゃくちゃ簡単です。(後述)
性能面でもいくつか軽量なモデルを試しましたが、一昔前のgpt-3.5等よりも性能が良いと感じてます。(当社比)
つまり、私のローカルLLMに対する課題と偏見を全てクリアしています!
そしてなんとこれがオープンソース!無料!
ついにLLMも本当の意味でオープンソース化したと思わせてくれたのがこのOllamaなんです!
という訳で今回はOllamaの導入方法をメインに、Writer FrameworkでChatBotを作ってみたいと思います。
Ollamaのインストール
Ollama公式ページで、「Download」ボタンから、ダウンロードしてインストールしましょう。

これでインストール終了です!
…いや、マジです。これで本当に終わりです。
詳しい使い方は公式や他の方々が色々記事にしてくださってますので割愛します。
Ollamaモデル準備
今回私はWindowsから行います。
MacでもLinuxでもやり方は大きく変わりません。
インストールしたOllamaアプリを起動した状態にして、コマンドプロンプトを開きましょう。
まずは問題なくインストールできたか、確認のため、
ollama -vと入力しましょう。

versionが表示されればOKです。
では次に今から使いたいローカルLLMをダウンロードしましょう。
とりあえずChatBot作りたいので、「llama3.2」をダウンロードします。
ollama pull llama3.2これでダウンロードが開始されます。
ダウンロードが終わったら、以下のコマンドで確認しましょう。
ollama list
Dockerみたいに確認できます。
これでOllamaに関する準備は以上です。
Writer Framework準備
ではChatBotを作りましょう。
まずはお使いの開発用の仮想環境をご準備いただき、Writer FrameworkとOllamaをインストールしてください。
pip install writer ollamaWriter Frameworkの使い方などの詳細については私の記事を参照ください。
基本的にこれで準備完了です。以下は私のおすすめでuvの場合の手順を紹介しています。
uvを使わない方は、次の「ChatBotの作成」まで進んでください。
補足:最近のおすすめ仮想環境「uv」
以下はuvを使った解説していきます。
インストール方法については割愛しますので、以下公式を参照ください。

poetryに関して、以前紹介しましたが、uvを知ったら戻れなくなりました。

まずはuvのPythonバージョンを3.12に設定しておきます。
uv python install 3.12プロジェクトを作りましょう
uv init ollama_chatbotollama_chatbotの部分はプロジェクト名なのでなんでもいいです。
次にカレントディレクトリを作成したプロジェクトに設定します。
cd ollama_chatbotではwriterとollamaを追加します。
uv add writer ollamaはい、これで必要なものの準備は全て終わりました!
ではこれからChatbotを作りましょう!
Chatbotの作成
以下のコマンドでWriter Frameworkのプロジェクトを作成しましょう。
uv run writer create llama_demollama_demoがプロジェクト名です。
次にプロジェクトのアプリを立ち上げます。
uv run writer edit llama_demo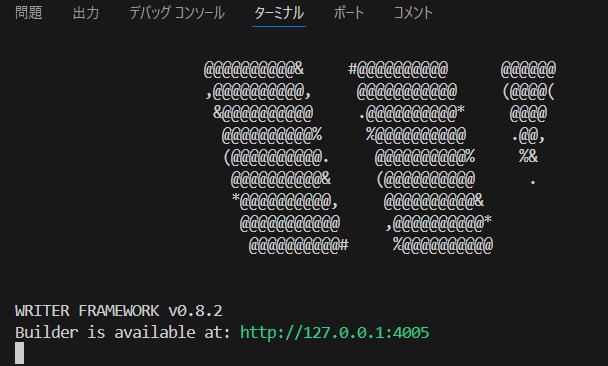
上記URLにアクセスすると、いつものアプリが立ち上がります。(また少し雰囲気が変わっている・・・!)
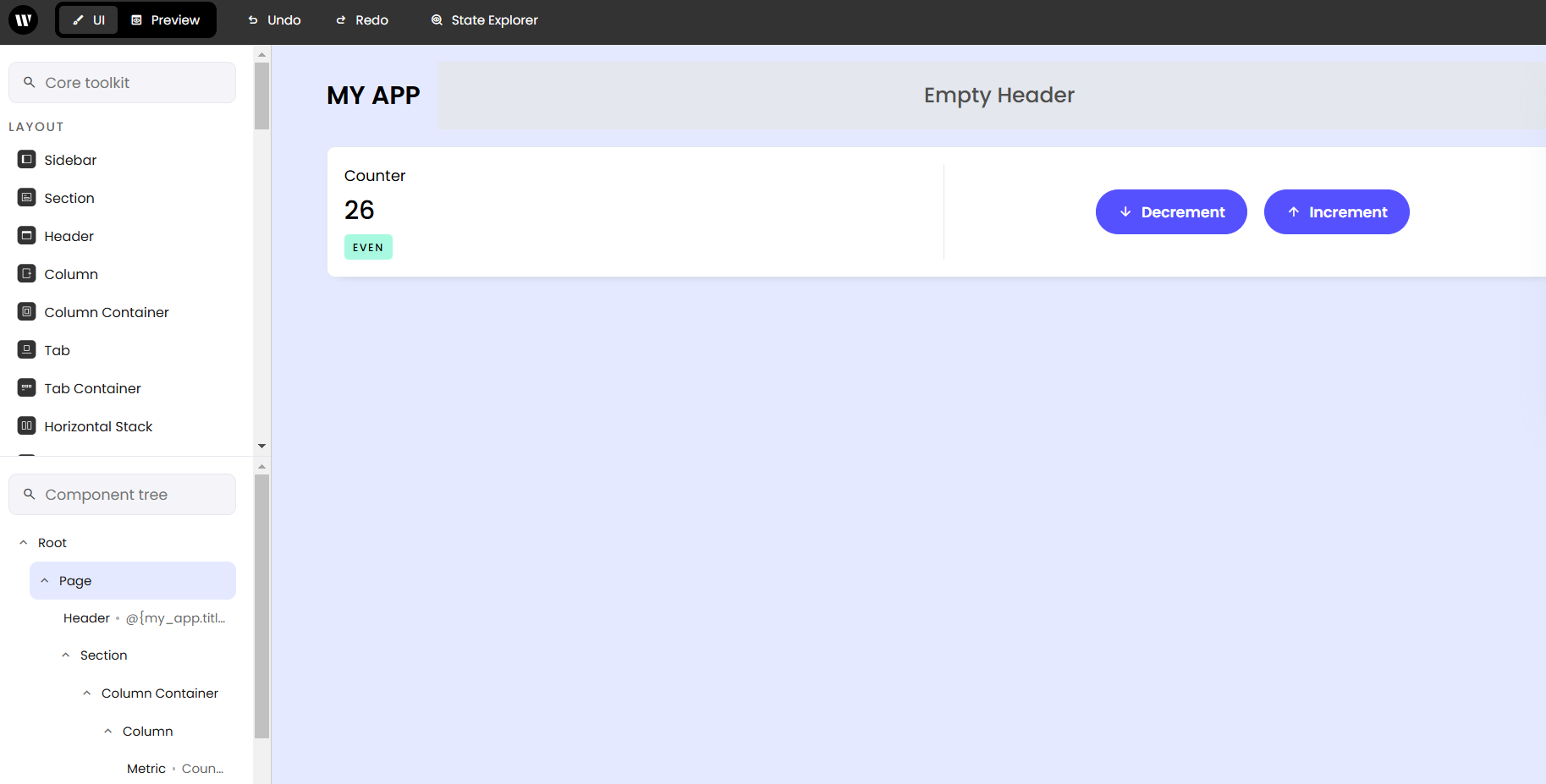
ただ別にいらないので、いつものようにSectionの中身は消しておきましょう。
消し方はいつも通りで、左側のSection以下の「Column Container」をクリックしてDelボタンで消えます。
空にしたら、左側のContentから「Chatbot」をドラッグアンドドロップしてください。
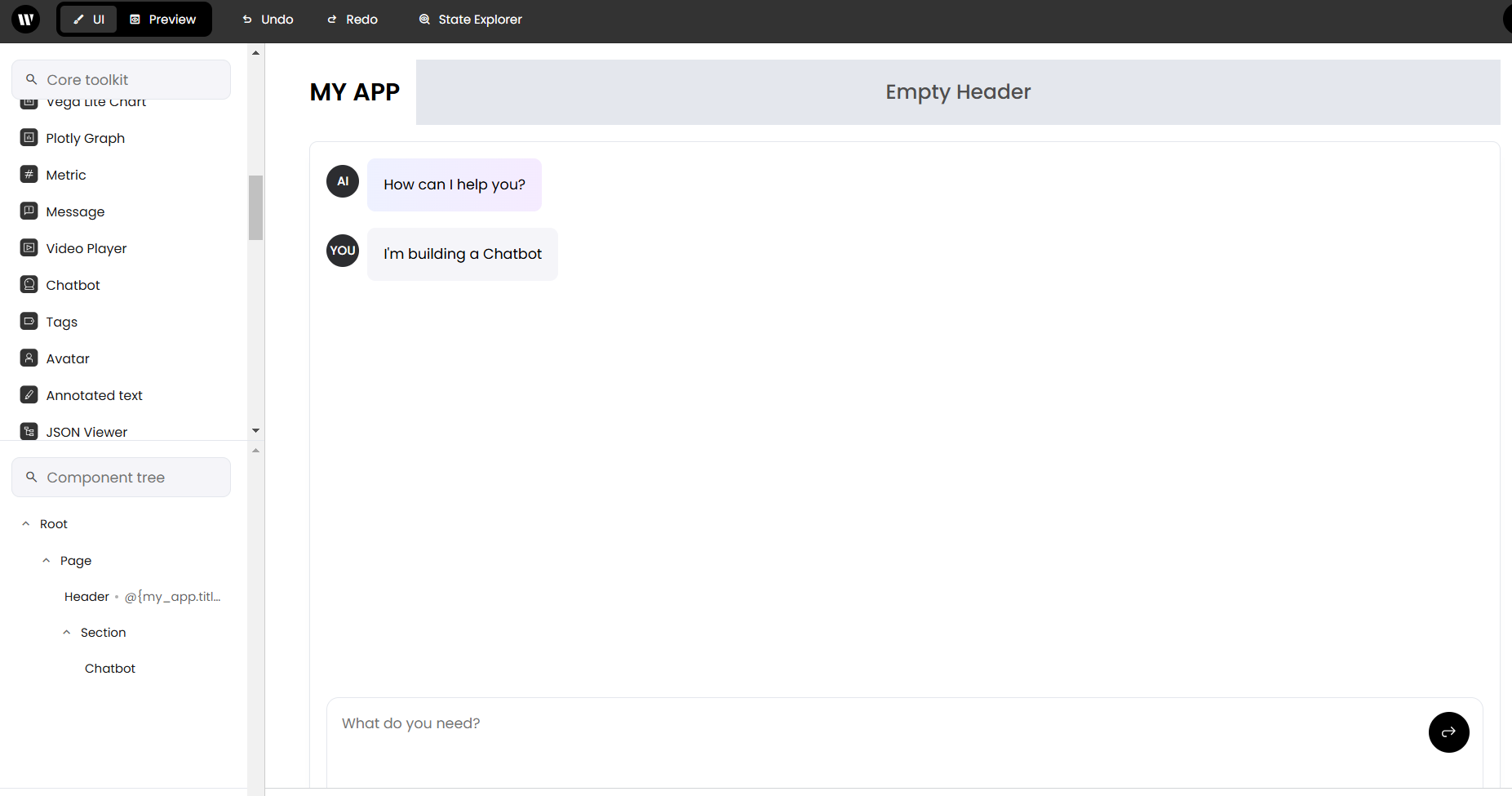
Chatbotエリアをクリックして、右側の歯車の「Expand Settings」をクリックして設定画面を開きます。
下の方の「Events」があるので、「wf-chatbot-message」の右にある「?」マークをクリックしましょう。
すると以下のサンプルコードが出るのでコピーします。
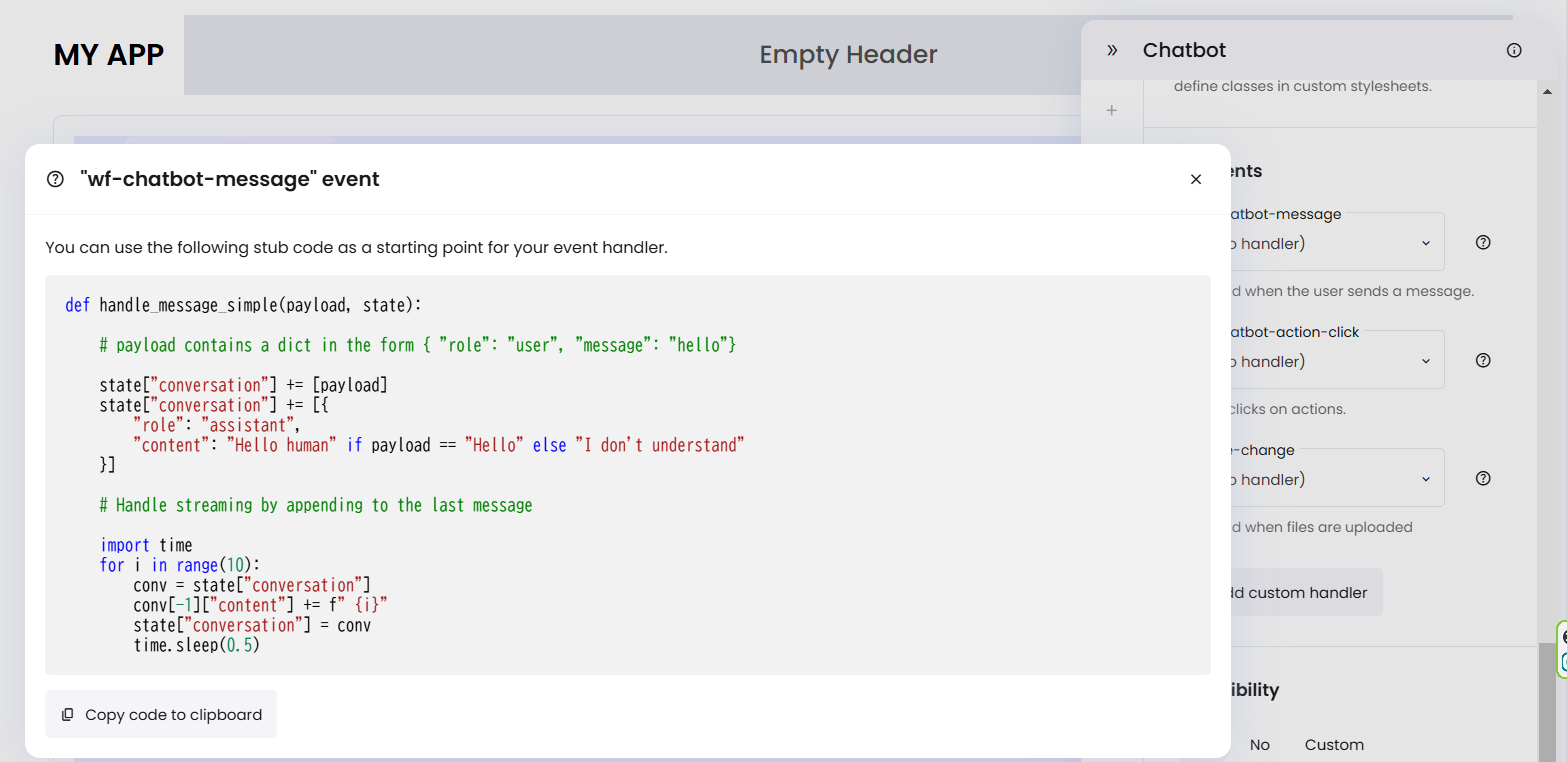
一旦フロントエンドを止めて、バックエンドに移ります。
llama_demoプロジェクトフォルダ内のmain.pyを開きます。
はい、これも大体要らないので、以下のように大体消してください。
消したら、先ほどコピーしたコードをmain.pyに貼り付けてください。
貼り付けたら、あとは以下のようにollamaのchatコードを追加し、initial_stateを修正します。
import writer as wf
from ollama import chat
from ollama import ChatResponse
def handle_message_simple(payload, state):
# user側のroleとcontent(query)を追加
state["conversation"] += [payload]
# queryに対する回答を追加
response: ChatResponse = chat(
model="llama3.2",
messages=[
{
"role": "user",
"content": payload["content"],
},
],
)
answer = response["message"]["content"]
state["conversation"] += [{
"role": "assistant",
"content": answer
}]
initial_state = wf.init_state(
{
"conversation":
[
{
"role": "assistant",
"content": "何かお手伝いできることはありますか?"
},
],
}
)
ollamaのコードは公式Gitのチュートリアルコードをそのまま使ってます。
payloadがユーザーが入力したクエリになり、roleとcontent(これ、公式コメントがmessageになってますが嘘です)を渡してくれます。
なので、contentをllama3.2に渡してあげて、回答をstate[“conversation”]につなげてあげればOKです。
余談ですが、WriterFrameworkはもともとLLMでの活用を想定されたツールですので、ollamaの登場でいよいよ本領発揮できる機会を得たんじゃないかと思います。
バックエンド側はこれで終わりです。
フロントエンドに戻りましょう。
先ほどのChatbotの設定画面の一番上に「conversation」の中身を全部消して、代わりに
@{conversation}入力途中に候補が出てきてくれると思いますが、init_stateのconversationをここに渡します。
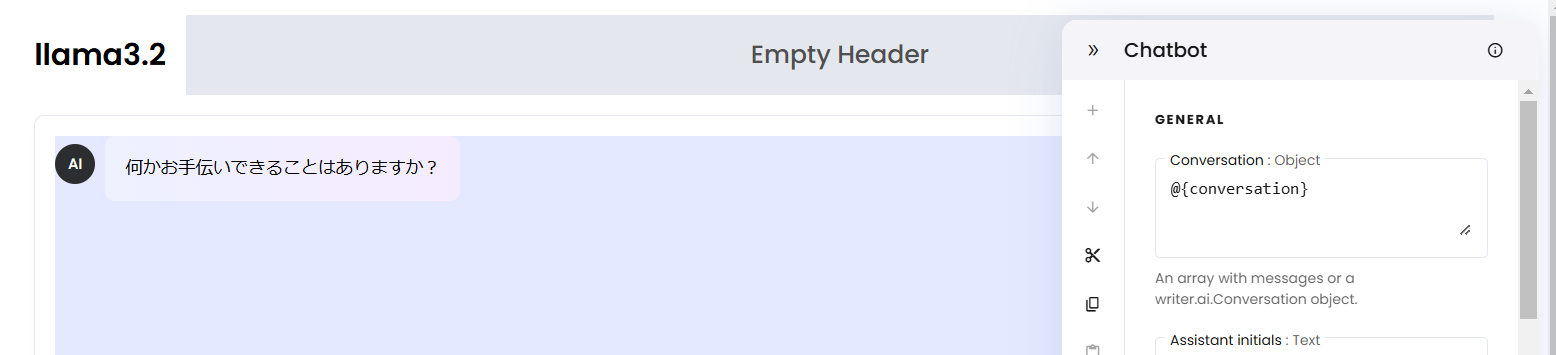
無事反映されましたね。
タイトルの「llama3.2」は私が勝手に入力したものなので、MyAppのままでも変えてもらってもかまいません。
最後に先ほどのEventの関数欄に候補が出てくると思いますので、main.pyの関数名を選択しましょう。

これで完成です!では何か聞いてみましょう!
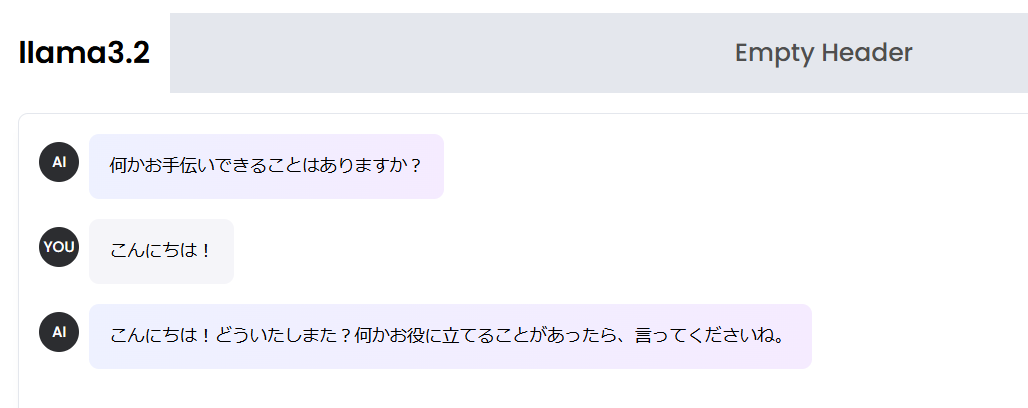
\キェェェェェェアァァァァァァシャァベッタァァァァァァァ!!!/

大体3secぐらいで返ってきました。
日本語だと少し怪しい返しですが、英語のほうだともう少しマシだったりします。
またモデルもllama3.1の方がサイズが大きくて精度が良いものもあるので、いろいろ試してみてください。
まとめ
今回はOllama+Writer Frameworkで爆速でChatBotを作ってみました。
ローカルLLMの精度の向上と導入しやすさが格段にあがってきてますね!
LLM開発でAPI叩くと、わずかとはいえお金がかかるのは心苦しいものがありました。
やっぱりそんな心配せずに、のびのびと開発できる方がいいですよね!
Writer FrameworkのChatBotですが、設定画面でファイルも受け取れます。
Ollamaにはllama3.2-visionというマルチモーダルなモデルもあるため、画像をインプットして解説させる、なんてこともできそうです。
OllamaはLangChainやLlamaIndexとも連携が可能なので、拡張機能の開発も進みそうです。
これらを使って快適なLLM開発を過ごしてください!
ここまでご覧いただきありがとうございました!
