
こんにちは。
今回はLLMの評価ツールとして、DeepEvalというライブラリが便利そうだったので紹介したいと思います。
LLMをはじめとするAIツールを使って開発するのがごくごく当たり前な日常になってきましたね!
進んだ企業などは自社業務に特化したLLMやAIツールの開発も盛んになってきています。
開発したLLMの品質を測るためには、LLMを評価する必要があります。
しかしLLMはこれまでの機械学習アルゴリズムのように、アウトプットが定型的なものではないため、定量的な評価が難しいため、定性的な評価になりやすい傾向にありました。
現在はLLMがLLMを定量的に評価するのが主流となっています。
DeepEvalもそんなLLMで評価するライブラリのひとつです。
LLMで評価するということは、やっぱり毎回APIを叩いてお高いんでしょう?と思いますよね。
当ブログをご覧になられている皆様ならお気づきでしょうが、もちろん、無料でできます!!
という訳で早速ご紹介していきたいと思います。
DeepEvalとは?
DeepEvalとは冒頭に書いた通り、LLMを評価するためのオープンソースライブラリです。
LLMに通したインプットに対して、アウトプットのクオリティを定量的に評価します。
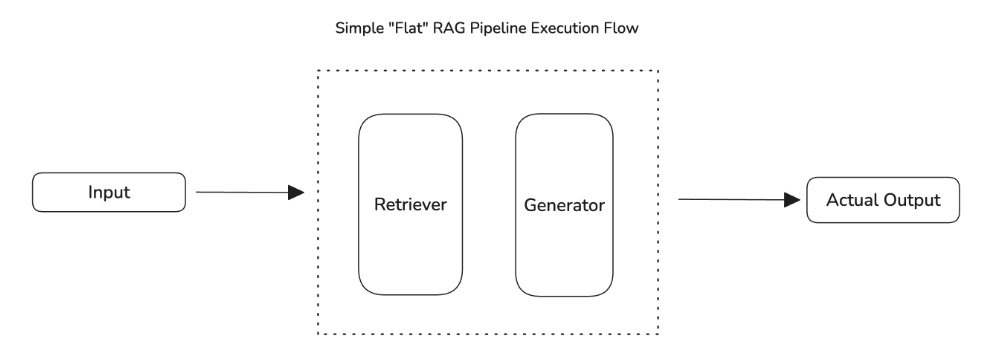
評価方法としてLLM専用のメトリクスがあり、DeepEvalでは30以上のメトリクスがあるようです。
本記事では例として「Summarization(要約)」をベースにご紹介します。
DeepEvalはPythonで記述することができ、非常にシンプルで短いコードで評価スクリプトを作成できます。
pip installで簡単に導入できるため、システムとして扱いやすいのもメリットです。
要約能力の評価方法
DeepEvalが要約能力をどのように評価するかについて触れておきます。
結論としてはalignment_scoreとcoverage_scoreというスコアで評価します。
- 要約に幻覚的な情報や元のテキストと矛盾する情報が含まれているかどうかを判断(alignment_score)
- 要約に元のテキストの必要な情報が含まれているかどうかを判断(coverage_score)
要するに事実にあっていて、余計な文章を含まずに要約できているかを評価しています。
この2つのうち、小さい方のスコアを採用しているようです。
従来の自然言語処理において、モデルの要約能力を評価する方法としてはBertScoreやROUGEといった手法があります。
BertScoreやROUGEについての説明は割愛しますが、これらの評価手法ではLLMを正しく評価できない可能性が高いのです。
例えばBertScoreなどのツールは、生成された要約と参照テキストの意味的類似性を評価する指標ですが、LLMが長い文章で要約を出力すると、類似性の高い単語が含まれてスコアが高くなってしまう傾向になります。
要約はシンプルで簡潔であるべきという観点を考慮すれば、この指標はそぐわないことがわかると思います。
ではalignment_scoreとcoverage_scoreはどのように計算しているのか。
それは以下のブログで解説されていますので、興味のある方は読んでみてください。
簡単にまとめると、LLMに質問して、「はい」か「いいえ」で回答させて原文と要約文の内容がどの程度一致しているか判断しているようです。
この質問文については、また後程コード内でも出てきますので、そこでも軽く触れようと思います。
要約に関する評価方法について把握した上で、実際に実装してみましょう。
実装
簡単に実装手順をまとめておきます。
まずは評価対象のインプット、アウトプットを用意します。
アウトプットにはGemini 1.5 Flashでインプットのテキストを要約したものを使います。
評価するモデルはGemini 2.0 Flashを使います。
DeepEvalはデフォルトがOpenAIですが、最近Geminiにも対応したようです。
これで無料でLLM評価ができるようになったというわけです。
インプット、アウトプットの用意
今回はこちらの日本語データセットを使用します。
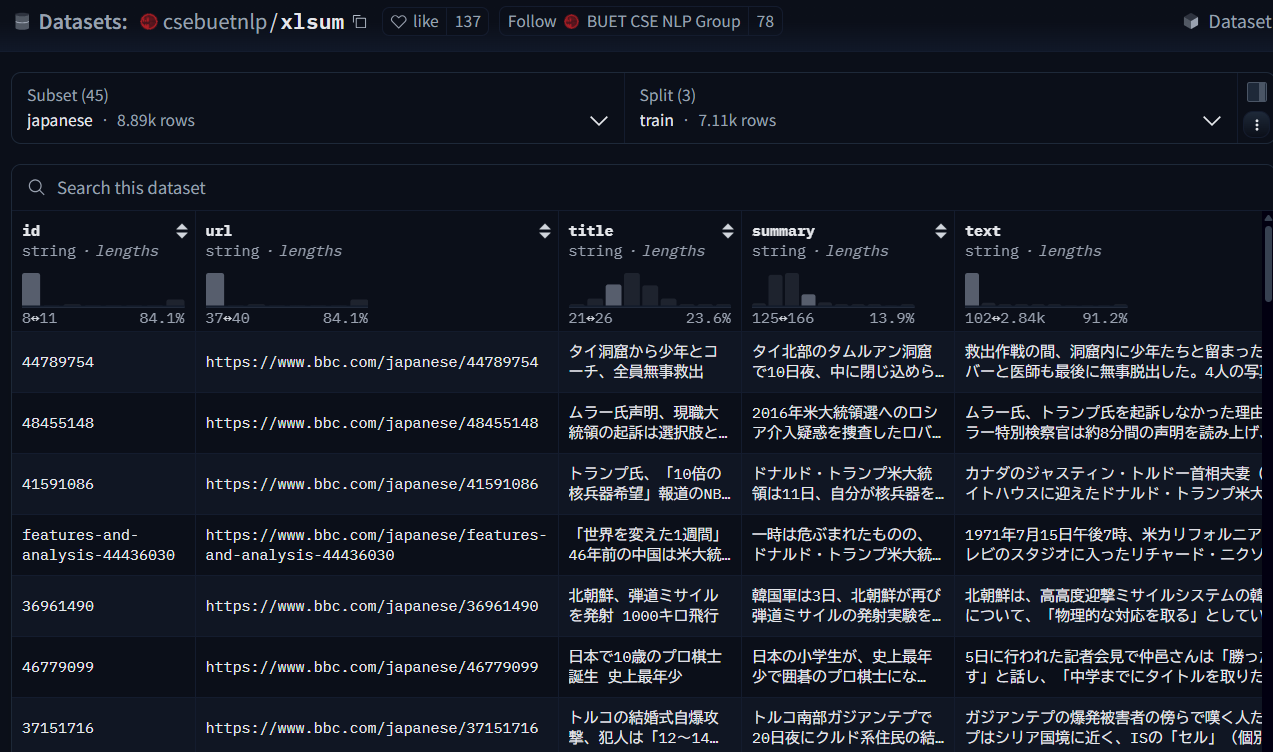
どれでもいいのですが、最近話題のトランプさんの名前が見えたので、上から3つ目のtextを一部使います。
長いので一部カットしたテキストで試します。
Geminiで実装
ではGeminiを使って評価スクリプトを作成します。
Geminiを使用するためにはAPIキーを取得する必要があります。
Gemini APIキーの取得方法についてわからない場合は以下の過去記事を参照ください。
まずはお使いの開発環境に以下の依存関係をインストールしましょう。
pip install deepeval google-genaiコードは以下になります。過去記事同様、APIキーは.envファイルで設定しています。
import os
from google import genai
from deepeval import evaluate
from deepeval.test_case import LLMTestCase
from deepeval.metrics import SummarizationMetric
from deepeval.models import GeminiModel
SUMMARY_MODEL = "gemini-1.5-flash"
EVAL_MODEL = "gemini-2.0-flash"
api_key = os.environ["GEMINI_API_KEY"]
input = """
カナダのジャスティン・トルドー首相夫妻(左と右)をホワイトハウスに迎えたドナルド・トランプ米大統領夫妻(11日)
トランプ氏は11日朝、「NBCやネットワークからこんなにフェイク・ニュースが出てくる状態で、いつになったら連中の免許を問題視してもいいんだ?
国にとってよくない!」とツイートした。 この後、カナダのジャスティン・トルドー首相夫妻をホワイトハウスに迎えたトランプ氏は、
報道陣を前に、NBCの報道を否定。その上で、「マスコミが書きたいことをなんでも書けるというのは、正直言って実に不快だ。誰かが調べるべきだ」と述べた。
核兵器の備蓄量を増やしたいのかとの質問には、「完璧な状態」に整えておく話をしただけだと説明した。
「そうじゃない。まったく完璧な状態に維持しておきたいだけだ。まさにそうしてる最中だ。核能力を」
「しかし今より10倍の量が欲しいと僕が言ったなどというのは、まったく不必要だ。信じてもらいたい」と大統領は重ね、
「僕が欲しいのは、刷新と完全な改良だ。最高の状態でないとならない」と強調した。 ジェームズ・マティス国防長官も、NBCの報道に反論。
長官は声明で、「大統領が米国の核備蓄拡大を求めたという最近の報道は、完全に事実と異なる」、「そのような誤った報道は無責任だ」と批判した。
「民主国家ではなくなる」 一方で、放送事業者の免許取り上げを示唆する大統領のツイートに対して、表現規制の懸念から強い反発の声が上がっている。
米ジャーナリスト保護委員会(CPJ)は、「NBCの放送免許に反対するべきだというトランプの主張によって、他の政府の独裁傾向も助長される」と非難した。
前オバマ政権の政府倫理局長を務めたウォルター・シャウブ氏は、突き詰めていけばいずれ「この国が民主国家ではなくなる状態」にまで達する恐れがあると警告した。
NBCニュースによると、トランプ氏は今年7月に国防総省で開かれた高官級会議で、米国の核備蓄量を劇的に増やしたいと政府幹部に話した。
米国の核兵器数が1960年代以降、減り続けていると図示する会議資料のスライドを見て、トランプ氏はそのように発言したのだという。
NBCは会議出席者3人の話として、出席者はトランプ氏のその要請に驚いたと伝えている。会議には統合参謀本部幹部とティラーソン国務長官も出席していた。
ティラーソン国務長官、「間抜け」発言報道に「そんなつまらないこと」 NBCによると、トランプ氏は核兵器以外にも米軍備の拡大を求めたという。
非営利の米軍備管理協会(ACA)によると、米国の核兵器は7100基、ロシアは7300基。
放送事業者の免許については、たとえ大統領が取り上げようとしても簡単にはできないだろうと言われている。
米国の放送事業者を監督する連邦通信委員会(FCC)は、系列を含めたネットワーク放送局全体に免許を交付しているのではなく、個別の地方局に与えている。
NBCはそのうち30近い地方局を傘下に収めている。 専門家たちは、報道内容が不公平だからという理由で、放送免許の交付は不当だと主張するのは難しいはずだとみている。
"""
# テキスト要約
print("gemini-1.5-flashで要約中...")
prompt = f"""
以下のテキストを要約してください。
テキスト:
{input}
要約:
"""
client = genai.Client(api_key=api_key)
response = client.models.generate_content(
model=SUMMARY_MODEL,
contents=[
prompt,
],
)
print("gemini-2.0-flashで評価中...")
actual_output = response.text
eval_model = GeminiModel(model_name=EVAL_MODEL, api_key=api_key)
test_case = LLMTestCase(input=input, actual_output=actual_output)
metric = SummarizationMetric(
threshold=0.5,
model=eval_model,
assessment_questions=[
"要約は元のテキストの主要な情報を網羅していますか?",
"要約は元のテキストの内容を正確に反映していますか?",
"要約は元のテキストの文脈を適切に保持していますか?",
"要約は元のテキストの重要な事実や数字を含んでいますか?",
"要約は元のテキストの論理的な流れを維持していますか?",
],
)
evaluate(test_cases=[test_case], metrics=[metric])
print(metric.measure(test_case))
print(metric.score, metric.reason)
inputに要約前のテキストデータを設定し、そのinputをgemini-1.5-flashで要約します。
要約結果にactual_outputを設定し、要約前のテキストデータと比較・評価するのがgemini-2.0-flashという流れです。
ここで引数にassessment_questionsというのがありますが、これがLLMが「はい」か「いいえ」で回答することで要約の質を判定する質問文です。
日本語の評価には日本語で設定しましょう。
それでは評価結果を見てみましょう。
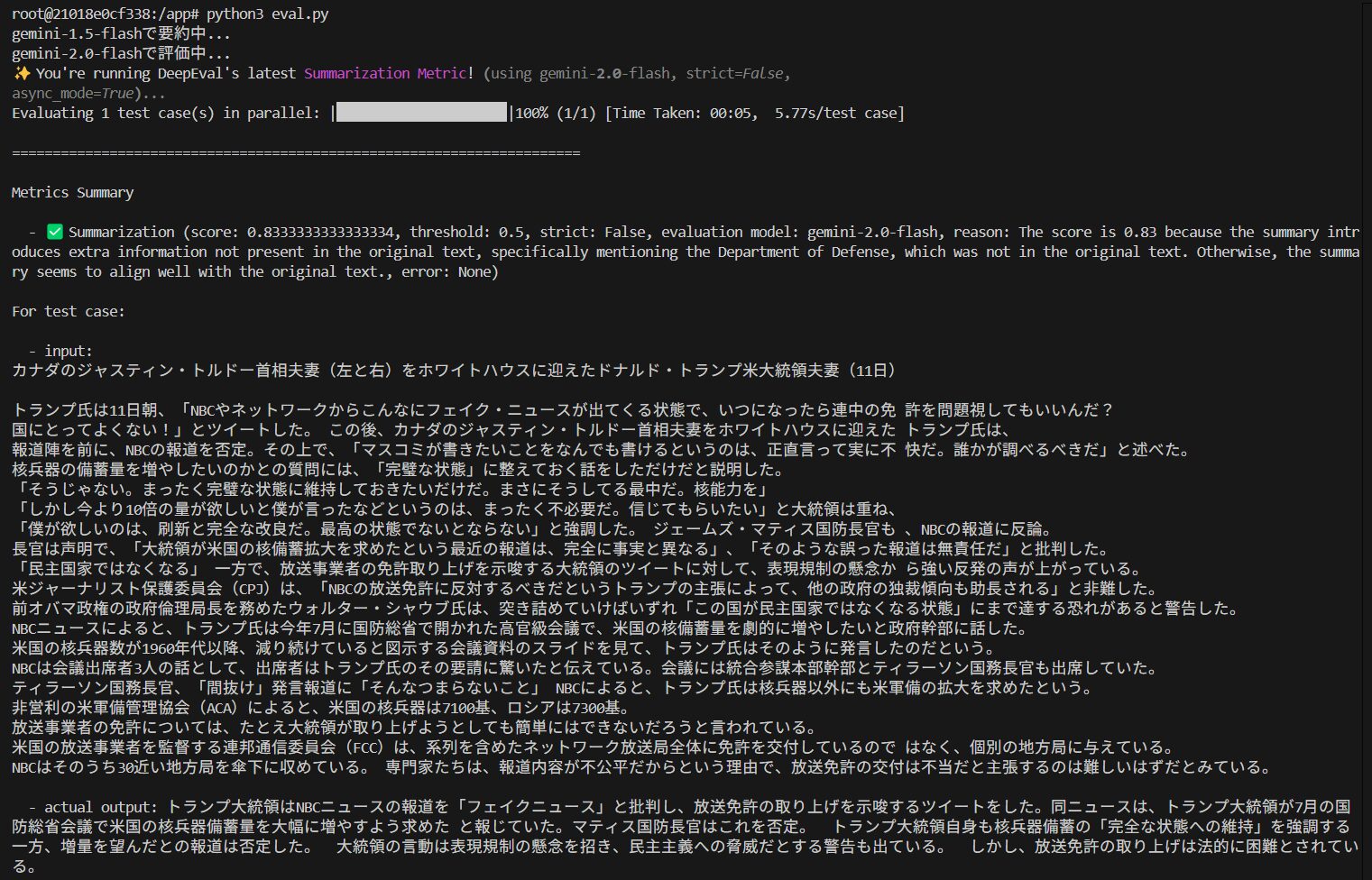
上手く要約できているようですね。
ちらっと眺めてもなんとなく要点を抑えてそうな要約だと思います。
さらにスクロールしていくと

assessment_questionsに対するtest結果ですね。
ちなみにassessment_questionsを日本語ではなく英語にすると0%になり、評価が失敗します。
評価対象と質問文の言語は一致させるようにしましょう。
最終的に以下のスコアと、その理由が返ってきます。

0.83ということは、概ね良さそうと見て良いでしょう。
理由について翻訳すると、
スコアが0.83なのは、要約が原文にはない追加情報、具体的にはトランプ大統領が核兵器備蓄の増強を求めたとされる会議の出席者に関する情報を提供しているためです。原文では政府関係者について言及されていますが、要約では国防総省の会議と明記されています。
結構細かくチェックしてますね。
コメントもなんだか専門家のような話しぶりです。
日本語でも問題なく評価できることがわかりました。
これなら確かに人が判断するレベルと遜色ありませんし、定量化もされています。
またLLMなので、人が定性的に判断することによるバラつきもかなり抑えられるように思います。
ただしLLMはうそをつく可能性があるため、全く人が見ないで結果を鵜呑みにするのはおすすめできません。
LLMにいくつかやらせてみて、その中の1つや2つを人が定性的に判断した結果と合わせて総合的に判断すると良いでしょう。
まとめ
今回はDeepEvalとGeminiを使ってLLMを無料で評価する方法について紹介しました。
LLMがどの程度の性能を出しているのか、評価する機会が増えるかと思います。
LLMの出力結果はなかなか定量的に判断するのは難しく、大変手間もかかります。
そんなLLMを定量的に判断するための手法が論文としていくつも公開されており、それらの手法をすぐ使える形にしてくれているのがDeepEvalです。
しかもオープンソースでコードの仕組みもとてもスマートでシンプルに組めるので、非常におすすめです。
Geminiと組み合わせれば、完全に無料でLLMの評価ツールが手に入ります。
LLMの性能評価でぜひ使ってみてください。
最後までご覧いただきありがとうございました!

