
こんにちは。
今回はWhisperなどの音声データを学習するモデルに有効なAugmentation手法である、SpecAugmentationを実装してみたので紹介していきます。
SpecAugmentationとは?
2019年にGoogleが開発した音声データに対するAugmentation手法のひとつです。

モデルの学習における過学習対策や性能向上として効果を発揮するようです。
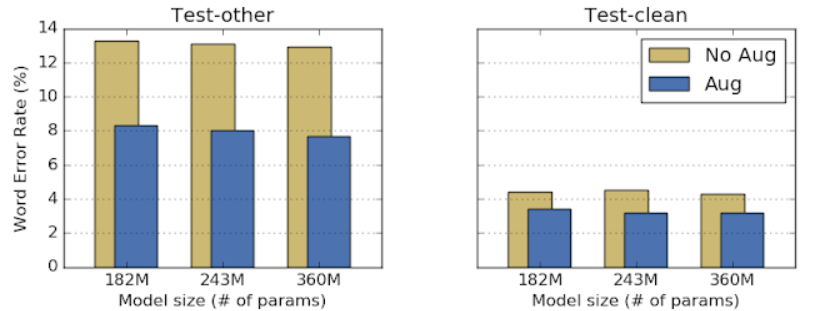
従来の音声データに対するAugmentationの違いとして、音声波形データからスペクトログラム化(短時間フーリエ変換による周波数、振幅、時間での変換)したデータに直接作用されることがあげられます。
スペクトログラム化の例として以下のような感じです。
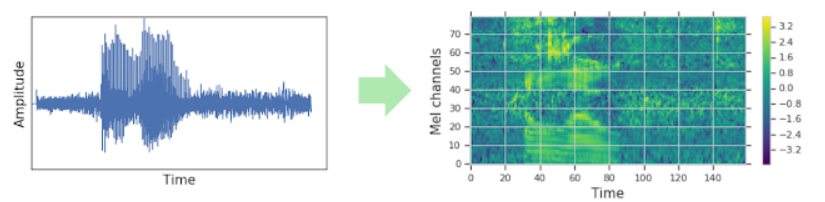
要するに生音声よりももっと細かく要素を分解して、それぞれの要素に作用できるというところがポイントです。
具体的な手法は3種類あげられてます。
Time Warping
スペクトログラムを時間方向に歪ませることで、時間的な変形に対するロバスト性をネットワークに学習させます。
音声としては局所的に速度が速くなったり遅くなったりする区間を発生させます。
Frequency Masking
周波数方向、上図でいうとy軸方向に対して一部をマスク(ゼロ埋め)します。
音声的には音の高さを変えたり、大きさに変化がでます。
Time Masking
時間方向、上図でいうとx軸方向に対して一部をマスク(ゼロ埋め)します。
音声的にはマスクした時間分ノイズが入るイメージです。
3種類のうち、2つはマスクしているので、画像でいうところCutOutの手法の音声バージョンという感じですね。
なので直感的にもAugmentationとしては成功しそうなイメージはあります。
以上の3種類を実装すれば、SpecAugmentationは実装できそうです。
既に実装例とか似たような記事があるのでは?
意外なことに、それらしいものが見つからなかったというのが本記事を書いたきっかけだったりします。
SpecAugmentationについて書かれた記事はあるのですが、論文の内容の紹介ばかりで、肝心の実装例とか検証例がないんですよね。
SpecAugmentationに対するGitとして、この辺が有力そうでした。
問題はTensorflowで書かれていたり、コード的にも一部気になるところがあるんですよね。(詳細は後述)
また宗教上の理由で私PyTorchかNumpyでの実装しか個人的には受け付けてないんですよね・・。
そんな私みたいな方が他にもいるだろうという思いと、実装に多少時間がかかったことも考慮して、今回の記事としてまとめた次第です。
実装(Numpy)
基本的には論文中の2.Augmentation Policyに書かれている内容をベースに、AIと対話しながら作成しました。
最終的なアウトプットが期待する形になっているかを確認しながら進めました。
まずは必要なライブラリとして、Numpyとscipyをお使いの開発環境にインストールしましょう。
pip install numpy scipyインストールしたら、これから作るスクリプトの先頭に、必要なライブラリをimportします。
import numpy as np
import scipy.ndimageあとは3つの主要機能を関数として作っていきましょう。
Time_Warping
def time_warping(spec, param_w=40):
"""時間方向のワーピング"""
num_mel_channels, num_frames = spec.shape
# num_frames が小さすぎる場合はワーピングせずにそのまま返す
if num_frames <= 2 * param_w:
return spec.copy()
# 中心となる時間フレームを選択
center = np.random.randint(param_w, num_frames - param_w)
# 対象ピクセルの元の座標グリッド
x, y = np.meshgrid(
np.arange(num_frames), np.arange(num_mel_channels)
) # x: time, y: mel
# ワープ量をガウス的に適用(時間方向にだけ変形)
displacement = param_w * np.exp(-((x - center) ** 2) / (2 * (param_w**2)))
# x座標だけずらす(縦方向(周波数)は固定)
x_new = x + displacement
y_new = y
# 座標の形を合わせて補間
coords = np.vstack([y_new.ravel(), x_new.ravel()])
warped = scipy.ndimage.map_coordinates(spec, coords, order=3, mode="reflect")
return warped.reshape(spec.shape)ランダムでワープする範囲を決めて、中心となるタイミングからランダムにワープして歪ませるイメージです。
論文中にもある、Tensorflowのsparse_image_warpをnumpyでやろうとすると、scipy.ndimage.map_coordinatesで実現可能なようです。
param_wが論文におけるWになります。
各コードでのparam_〇は、論文におけるTable1に対応させてます。
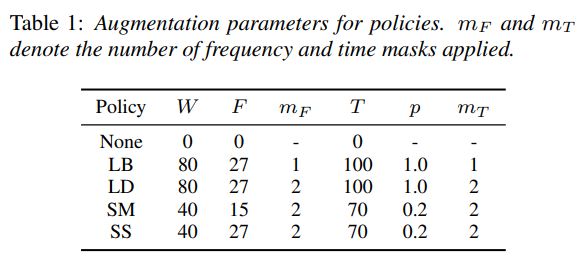
ちなみにデフォルト設定はSSにしていますが、ここはデータによって調整しましょう。
また短すぎる音声データだと、ランダム決めでエラーが起こるため、warpingを実施しない場合もあります。
# num_frames が小さすぎる場合はワーピングせずにそのまま返す
if num_frames <= 2 * param_w:
return spec.copy()Freq_Masking
def freq_masking(spec, param_f=27, num_masks=2, mask_value=0):
"""周波数方向のマスキング(mask_value を追加)"""
spec = spec.copy()
num_mel_channels = spec.shape[0]
for _ in range(num_masks):
if param_f < 1:
continue
f = np.random.randint(1, param_f + 1) # f が 0 にならないように調整
f0 = np.random.randint(0, num_mel_channels - f + 1)
# マスキング適用(ゼロ埋め or ノイズ)
if mask_value == 0:
spec[f0 : f0 + f, :] = 0
else:
noise = np.random.normal(0, 1, (f, spec.shape[1])) * np.mean(spec)
spec[f0 : f0 + f, :] = noise
return specほとんどGitと同じ書きっぷりです。Numpyでも同じように書けます。
Time_Masking
def time_masking(spec, param_p=0.2, param_T=40, num_masks=2, mask_value=0):
spec = spec.copy()
num_frames = spec.shape[1]
# 全体でマスクしてよい最大量
max_total_mask = int(param_p * num_frames)
# 1回のマスク最大長さTをpに応じて制限
adjusted_T = min(param_T, max_total_mask // num_masks) if num_masks > 0 else 0
for _ in range(num_masks):
if adjusted_T < 1:
continue
t = np.random.randint(1, adjusted_T + 1)
t0 = np.random.randint(0, num_frames - t + 1)
if mask_value == 0:
spec[:, t0 : t0 + t] = 0
else:
noise = np.random.normal(0, 1, (spec.shape[0], t)) * np.mean(spec)
spec[:, t0 : t0 + t] = noise
return spec実はGitをみると、pはinitで設定しているものの、Time_Maskingで全く使われてないんですよね・・。
論文で確認してみると、おそらく以下の部分が考慮されてないんですよね。
We introduce an upper bound on the time mask so that a time mask cannot be wider than p times the number of time steps.
要するにTは最大マスク上限だが、全体のフレーム数のp倍を超えるようならp倍で頭打ちにする、ということだと思います。
特に短い音声データなどで、Tを優先してしまうと全部音声データがマスクされてる、なんてことが起こりそうです。
LBやLDみるとp=1.0なので、全体をマスクしても問題ないケースならOKです。
ただ全体のフレーム数以上のTを許可してしまうと、コードの挙動上エラーが出る可能性があるため、pなどの上限設定は必要だと思います。
以上でSpecAugmentationの各機能の実装は完了です。
SpecAugmentation
ではこの3つを順番に実行するものとして、SpecAugmentation関数を作成します。
例えば以下のようになります。
def spec_augment(
spec,
param_w=40,
param_f=15,
param_T=40,
param_p=0.2,
num_freq_masks=2,
num_time_masks=2,
prob=0.5,
):
if np.random.rand() < prob:
spec = time_warping(spec, param_w=param_w)
spec = freq_masking(spec, param_f=param_f, num_masks=num_freq_masks)
spec = time_masking(
spec, param_p=param_p, param_T=param_T, num_masks=num_time_masks
)
return specspecにはスペクトログラム化されたデータを受け取ります。
口述しますが、librosaの短時間フーリエ変換されたものであれば受け取れます。
またtransformersのWhisperProcessor.from_pretrainedなどでfeature_extractorした出力結果もスペクトログラム化されたものになりますから、Whisperモデル用のデータにも使えます。
Augmentationは一般的に50%の確率で実施されるため、prob=0.5を追加しました。
ここら辺はどの程度どの機能を実施するかで工夫しても面白いかもしれません。
では実際に動かしてみましょう。
動作確認
音声データのスペクトログラム化のために、pythonではおなじみのlibrosaを使います。
お使いの開発環境にlibrosaを追加しましょう。
またどのようにwarp, maskされたか可視化するため、matplotlibも追加しましょう。
pip install librosa matplotlib例えば以下のように動かせます。
if __name__ == "__main__":
import librosa
import librosa.display
import soundfile as sf
import matplotlib.pyplot as plt
# 音声ファイルの読み込み
input_file = "test.mp3"
y, sr = librosa.load(input_file, sr=None)
# 短時間フーリエ変換(STFT)を取得
stft_spec = librosa.stft(y, n_fft=1024, hop_length=512)
stft_magnitude, stft_phase = np.abs(stft_spec), np.angle(stft_spec)
stft_db = librosa.amplitude_to_db(stft_magnitude, ref=np.max)
# Augmentationを適用
augmented_stft_db = spec_augment(stft_db)
# 変換後のスペクトログラムから音声を再構成
augmented_stft_magnitude = librosa.db_to_amplitude(augmented_stft_db)
augmented_stft = augmented_stft_magnitude * np.exp(
1j * stft_phase
) # 位相情報を復元
y_aug = librosa.istft(augmented_stft, hop_length=512) # Griffin-Lim不要
# 音量を元に戻す(正規化)
y_aug = y_aug * (np.max(np.abs(y)) / np.max(np.abs(y_aug)))
# 結果を保存(音声)
sf.write("original.mp3", y, sr)
sf.write("augmented.mp3", y_aug, sr)
# スペクトログラムの可視化と保存
fig, ax = plt.subplots(2, 1, figsize=(10, 8))
librosa.display.specshow(stft_db, sr=sr, x_axis="time", y_axis="log", ax=ax[0])
ax[0].set_title("Original STFT Spectrogram")
librosa.display.specshow(
augmented_stft_db, sr=sr, x_axis="time", y_axis="log", ax=ax[1]
)
ax[1].set_title("Augmented STFT Spectrogram")
plt.tight_layout()
plt.savefig("spectrogram_comparison.png") # 画像として保存短時間フーリエ変換したものをSpecAugmentation関数に通すだけです。
あとは音声データに戻して、どのようにSpecAugmentationされたのかを比較するために可視化したコードになります。
ちなみに一例の結果も貼っておくと、こんな感じです。
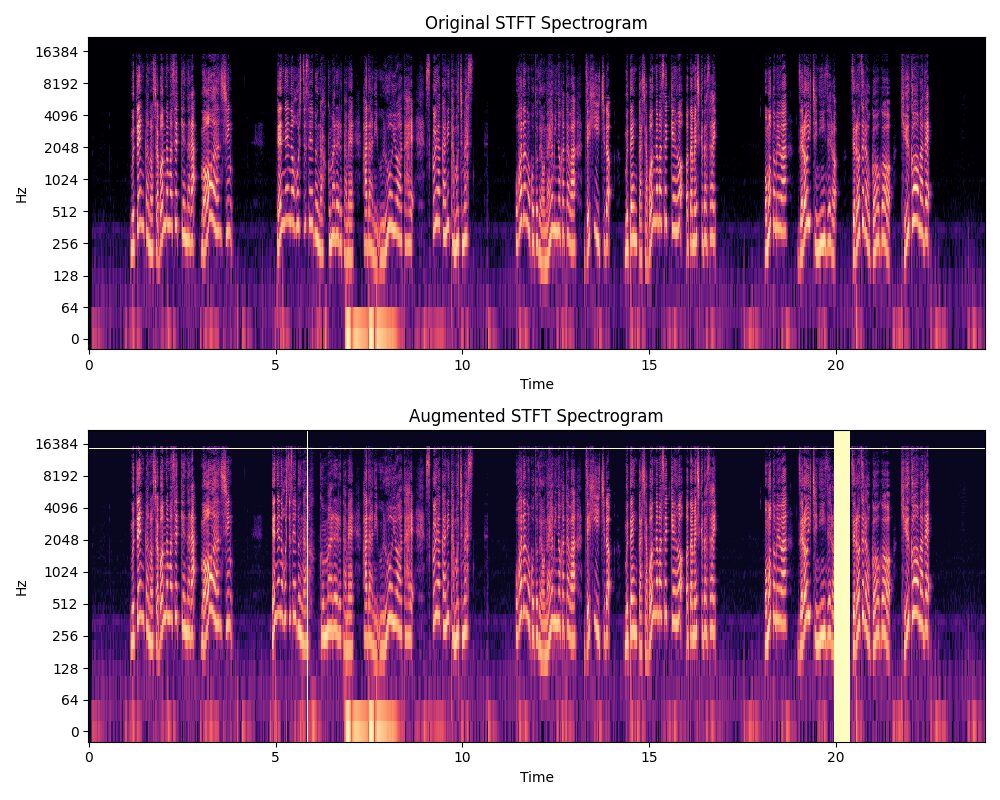
黄色く十字で入ってる部分がマスクされた箇所です。
またwarpingについては非常にわかりづらいですが、5~7secあたりが狭くなったり引き伸ばされたりしてるのがわかりますか?
実際の音声も聞き比べてみましょう。
original
augmented
どうでしょうか?結構違いはハッキリわかるのではないでしょうか?
このように音声データにバリエーションを持たせることで、ファインチューニングを効果的に進めることが期待できそうです。
まとめ
今回はSpecAugmentationの実装について紹介しました。
Whisperなどの音声認識モデルもかなり普及してきました。
よりユースケースにあったファインチューニングなども必要な方がいるかもしれません。
そんなとき性能向上で困ったときに、SpecAugmentationを試してみてはいかがでしょうか?
余談ですが、torchaudioというライブラリにもSpecAugmentationはあります。

これ使おうかと思ったんですけど、若干論文と引数が違ったり、実装しにくくて断念したんですよね。
使ってる人の記事とかも見かけなかったので、やはり不評なんでしょうかね。
Augmentationで大事なのは、想定通りのデータ拡張ができていることを確認することです。
今回のSpecAugmentationを使う際も、データがどのように加工されているかはきちんと確認しながら使いましょう。
音声認識モデルのファインチューニングを実施する際の参考になれば幸いです。
ここまでご覧いただきありがとうございました!

