
こんにちは。
今回は以前ご紹介したPythonライブラリのPyGWalkerに、新しい機能としてPaint機能が追加されましたので、これについて紹介します。
「PyGWalkerって何?」という方は以下のブログをご覧ください。
このPaint機能は一言でいうと、「データの民主化を図った、新時代なデータ分析ツール」で、実はこの機能は私が長年欲しいと思っていた機能でもあります。
今回はそんなPyGWalkerのPaint機能について、何ができて何がそんなにすごいのかをご紹介したいと思います。
PyGWalker準備
動きを見るのが一番早いので、さっそくコードを書いていきます。
皆さんも良かったら触ってみてください。
サンプルコードは公式サイトの以下のページにあるので、そこから丸々コピペします。

from pygwalker.api.streamlit import StreamlitRenderer, init_streamlit_comm
import pandas as pd
import streamlit as st
# Streamlitページの幅を調整する
st.set_page_config(
page_title="StreamlitでPygwalkerを使う",
layout="wide"
)
# PyGWalkerとStreamlitの通信を確立する
init_streamlit_comm()
# タイトルを追加
st.title("StreamlitでPygwalkerを使う")
# PyGWalkerのレンダラーのインスタンスを取得する。このインスタンスをキャッシュすることで、プロセス内メモリの増加を効果的に防ぐことができます。
@st.cache_resource
def get_pyg_renderer() -> "StreamlitRenderer":
df = pd.read_csv("https://kanaries-app.s3.ap-northeast-1.amazonaws.com/public-datasets/bike_sharing_dc.csv")
# アプリをパブリックに公開する場合、他のユーザーがチャートの設定ファイルに書き込めないように、デバッグパラメータをFalseに設定する必要があります。
return StreamlitRenderer(df, spec="./gw_config.json", debug=False)
renderer = get_pyg_renderer()
# データ探索インターフェースをレンダリングする。開発者はこれを使用してドラッグアンドドロップでチャートを作成できます。
renderer.render_explore()これを動かすときはpip installでpandas, streamlit, pygwalkerをインストールしてください。
Dockerをお持ちの方はすぐに起動できるGitもご用意してますので、良かったら以下を参照ください。
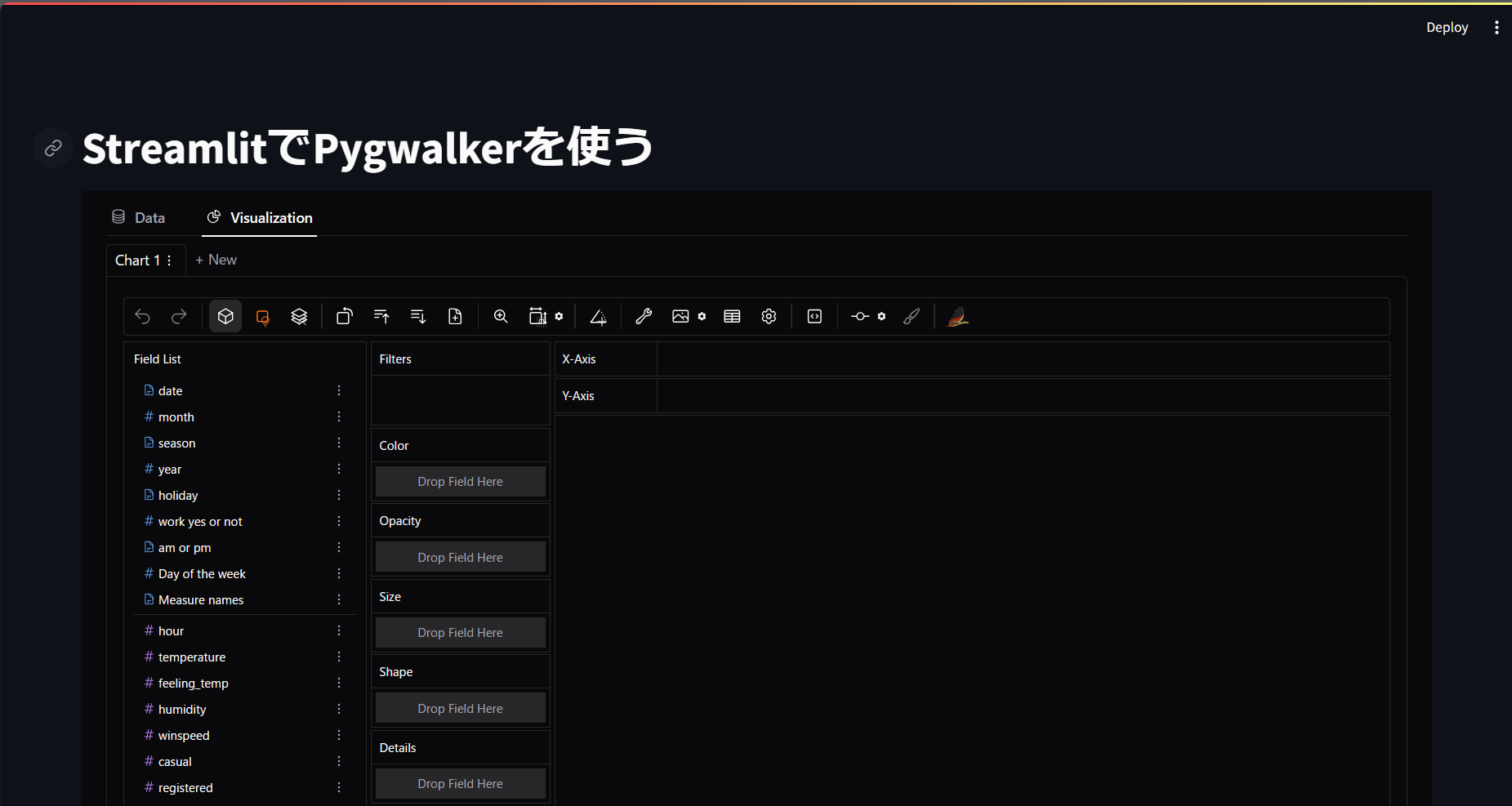
ではPyGWalkerをStreamlitで起動してみましょう。
起動すると以下のような画面が確認できればOKです。
またとりあえず試してみたいという方は、Graphic Walkerでも同じことができます。
以下のリンクの「Playground」ボタンから同様の画面が立ち上がります。(アカウント作成も不要で、無料で動かせます)

「Create Dataset」ボタンから、「Public Dataset」→「Bike Sharing」→「Submit」で準備OKです。
それでは早速Paint機能についてみていきましょう。
Paint機能とは?
ではPaint機能を確認するデータの準備をします。
まずは「Aggregation」を外します。(これ外すのがデフォにしてほしいな・・)
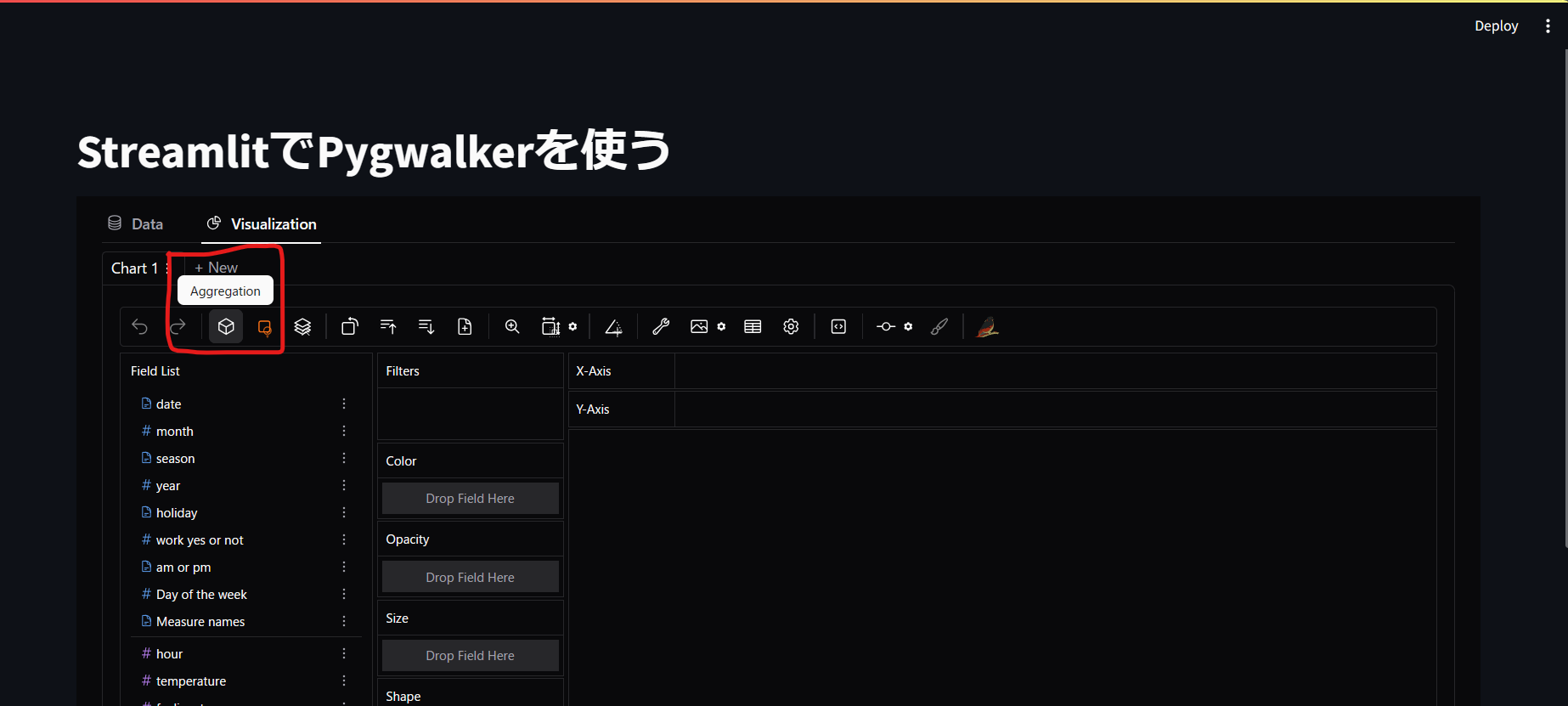
次にX-Axisにcausal, Y-Axisにregisteredをドラッグアンドドロップしてください。
そしてLayoutModelをAuto→Containerにしてください。
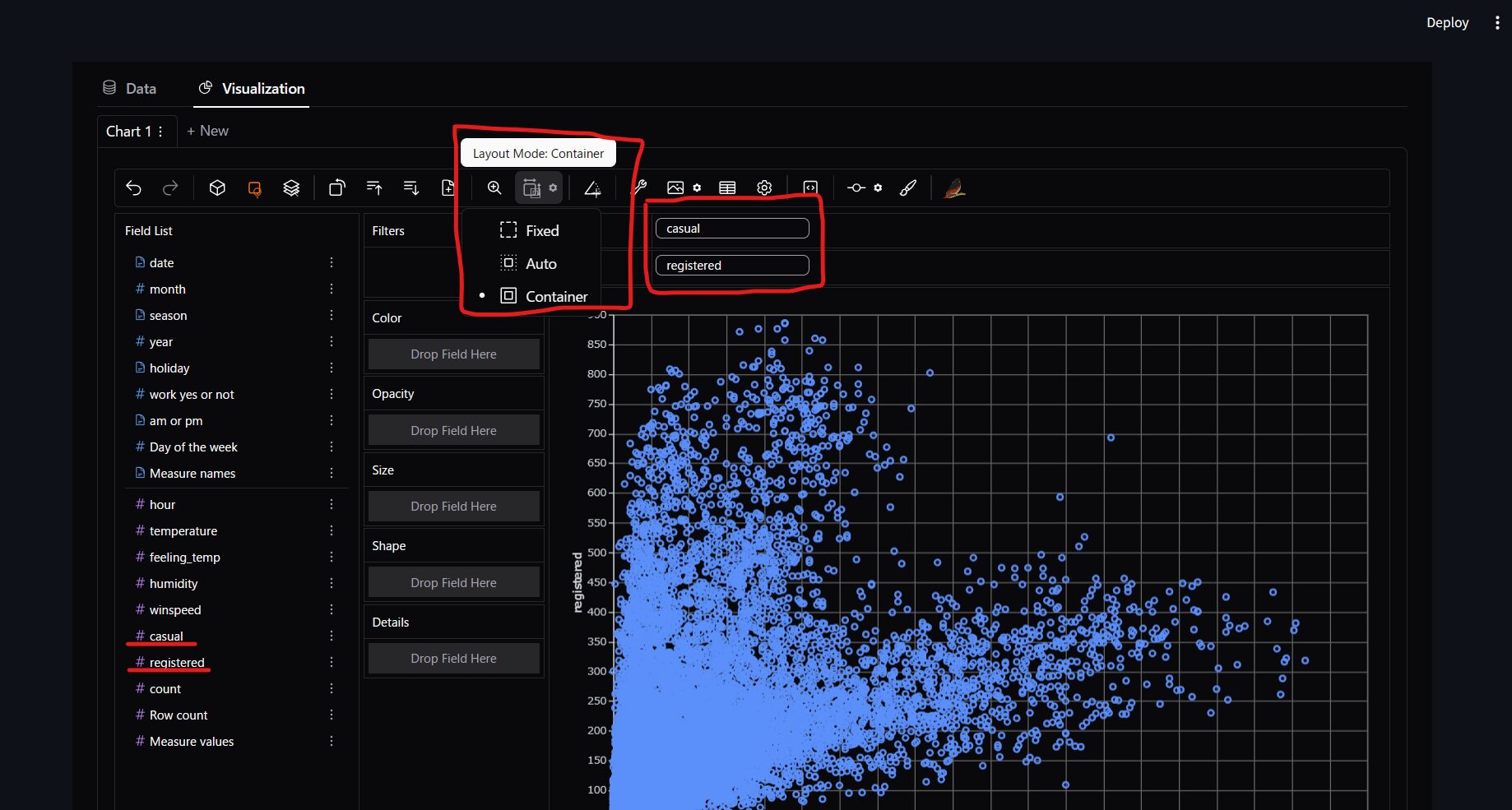
これでデータの準備はOKです。
さて、Paint機能ですが、これは「アノテーションをGUIで行う」機能になります。
筆のマークの「Open Painter」をクリックします。
すると以下のような画面が立ち上がります。
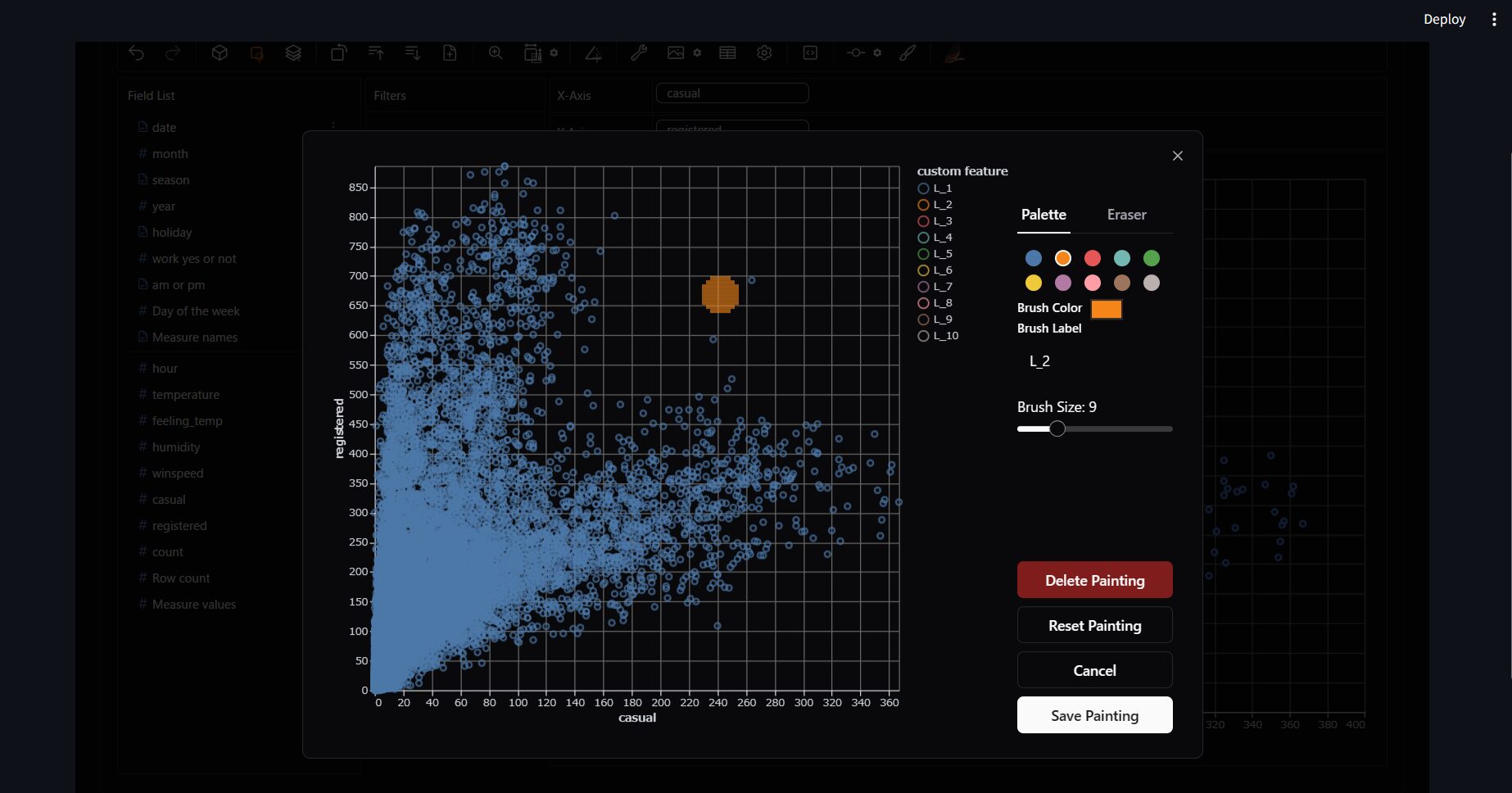
適当にドラッグしてみてください。すると、データに色がついたことが確認できると思います。
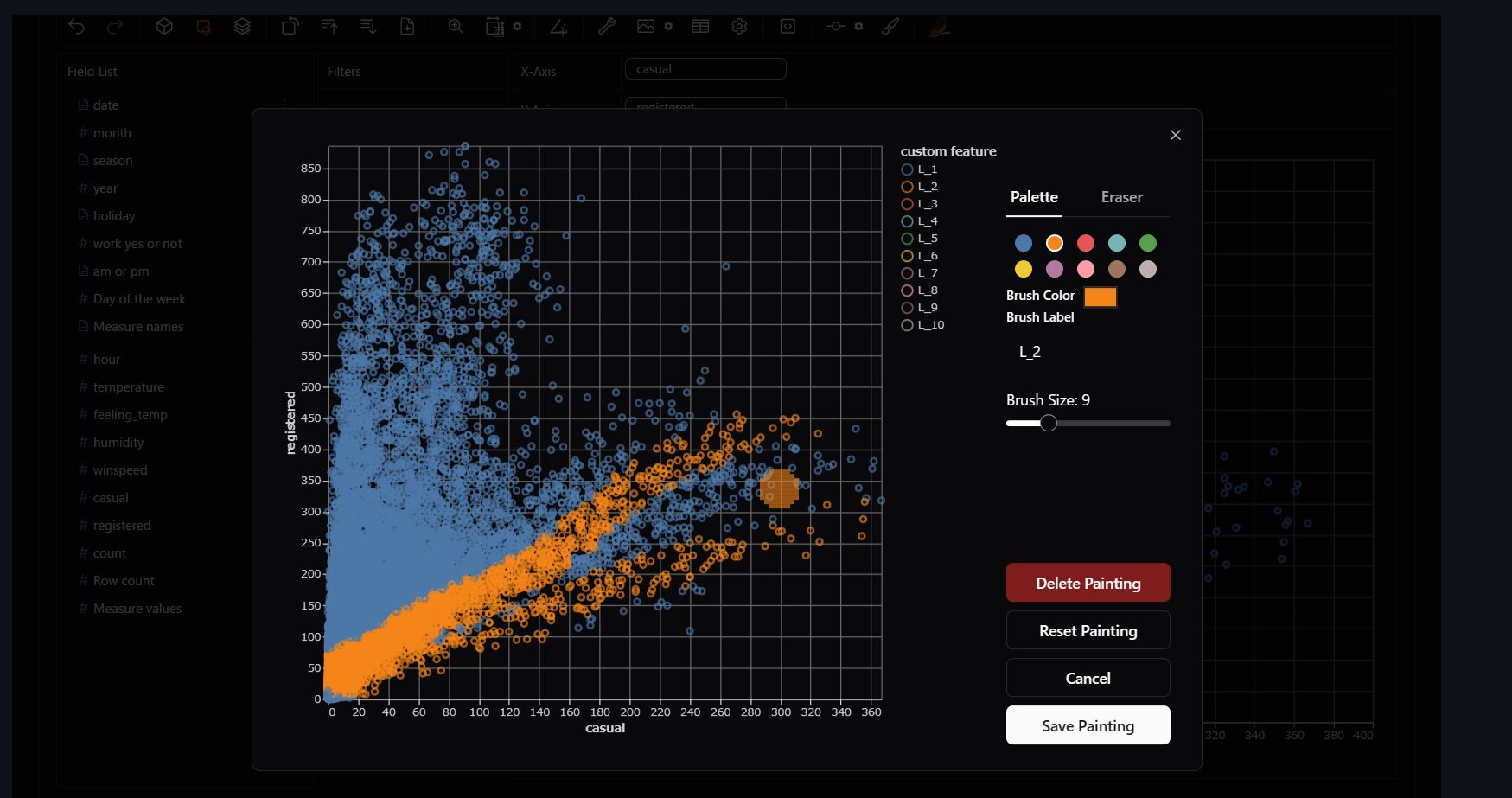
色を付けたら「Save Painting」で元の画面に戻ります。
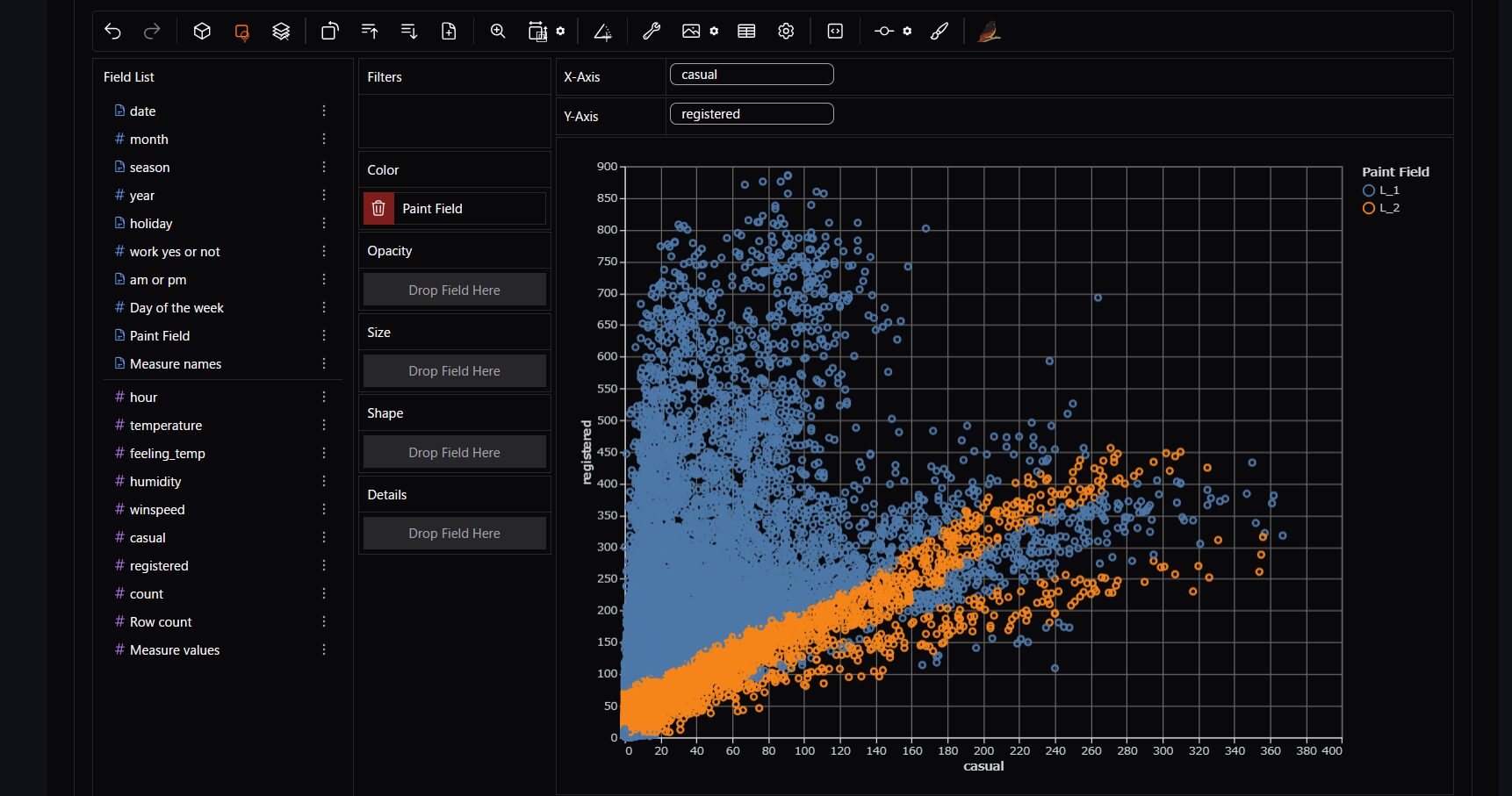
右上に凡例として、青丸に「L_1」、黄丸に「L_2」というラベルがついたことがわかります。
本当にアノテーションがうまくいっているか、歯車アイコンの左にあるテーブルアイコンで「export csv」をしてみましょう。
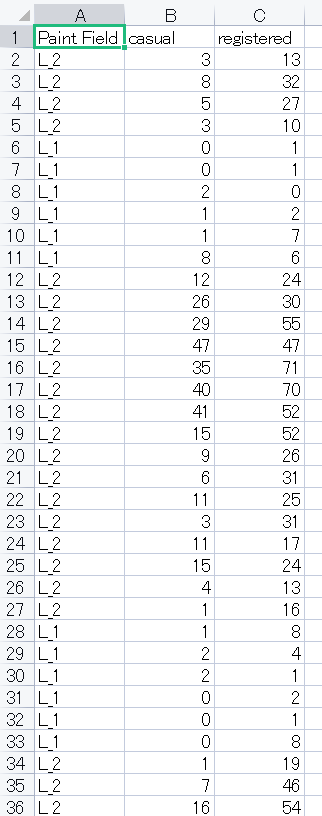
この結果からわかる通り、元のデータセットのデータフレームからxとyに指定した列名を抽出し、ペイントした行に対してラベルをつけてくれるのです。
これ何がすごいかって、ユーザーの視覚的・感覚的にアノテーションつけられるのがすごい便利ですね。
プログラム書ける人でも、アノテーションつけるロジック考えたり、下手したら手作業でつけてたかと思うんです。
でもこれでプログラム書けない人でもアノテーション作業ができるし、プログラムで大変だった人も劇的に楽になると思うんですよ。
まさに「データの民主化を図った、新時代なデータ分析ツール」だと思いませんか?
そしてこのPaint機能はペイントするだけではありません。
ラベルをつけられるということは、つけたラベルの行を消すこともできるという発想で、「Eraser」機能もあるんです。
先ほどの筆マークに戻って、「Delete Painting」で一旦色を付けたものは元に戻しましょう。
「Palette」の隣にある「Eraser」を押してください。
あとはさっきと同じ要領で、ドラッグしてみましょう。
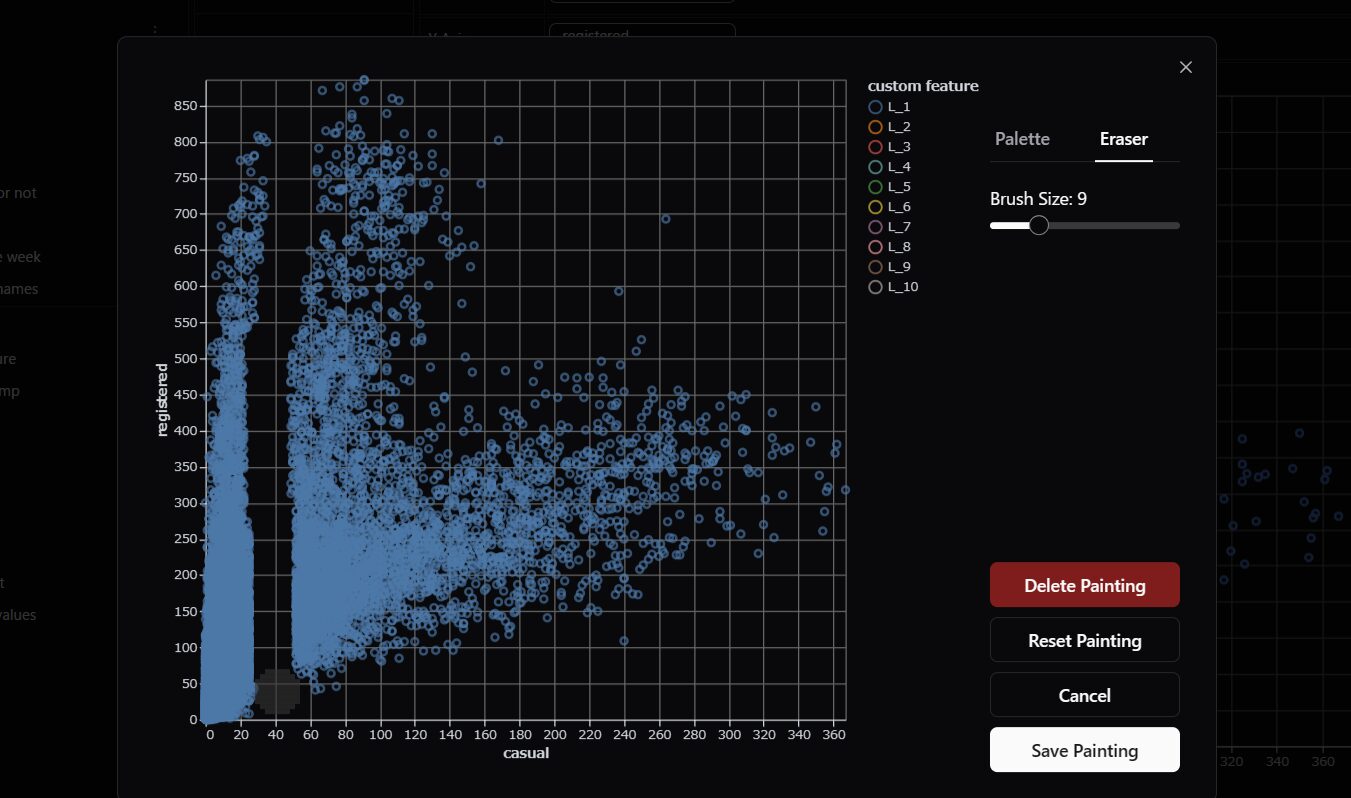
データが消えましたね。消えたら「Save Painting」で保存します。
確認のためにCSVを出力する方法もありますが、Eraserの場合は他に確認する方法があります。
「Paint Field」という枠をクリックすると、空白ラベルを付与された数が表示されます。(これPaletteの時も見えるようにしてほしい)
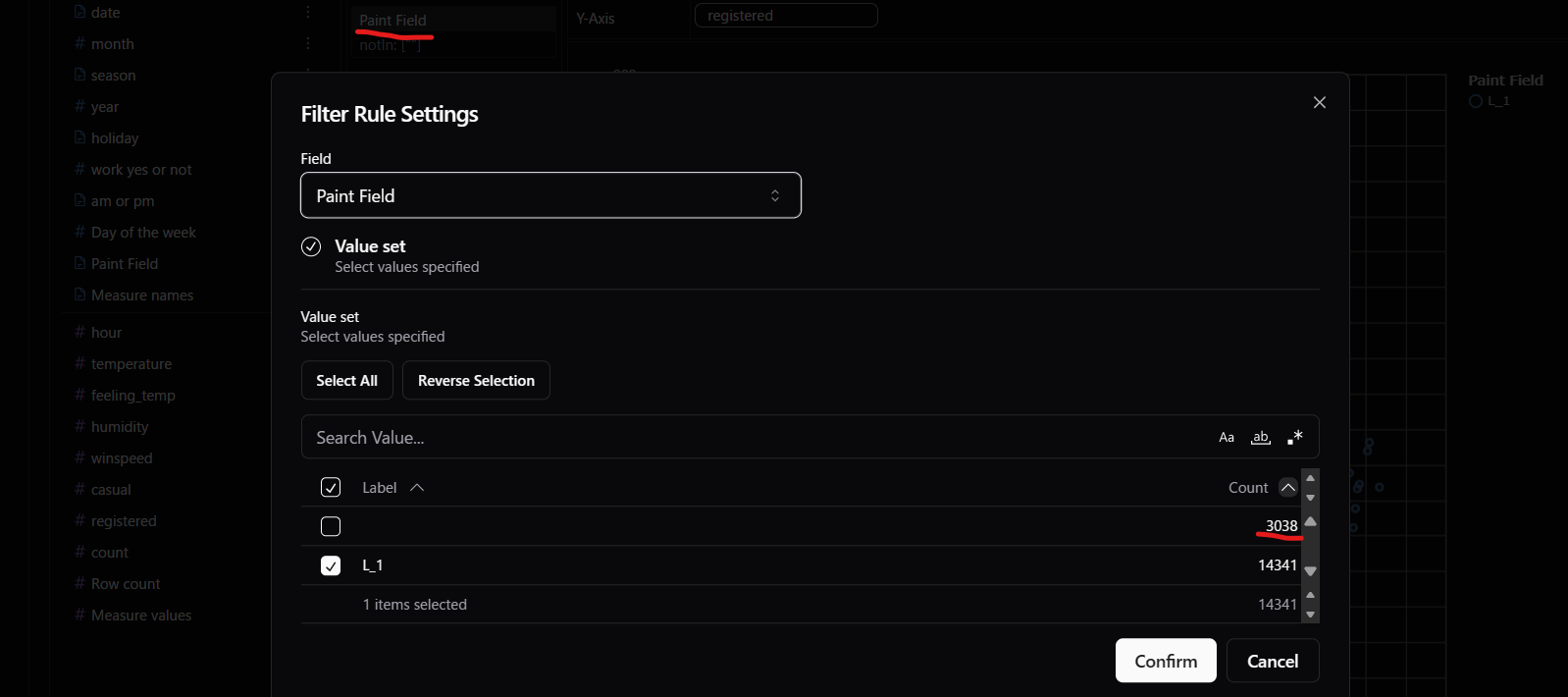
消した数は3038個であることがわかります。
このように、例えば外れ値であったり、データセットを何らかの理由で特定の箇所だけ削除したい場合に可視化しながら作業ができるというのはとても便利です。
これも従来ではプログラマーがコードを書いたり手作業で修正したりと地味で大変だったものがあっという間にできてしまうようになったのは、新時代をとても感じるツールだと思います。
まとめ
いかがだったでしょうか?
今回はPyGWalkerに新しく追加されたPaint機能についてご紹介しました。
PyGWalkerはStreamlitとも相性が良いので、プログラムを書かない人でもアプリを共有してデータセットを設計することが容易になったと思います。
これにより、ドメイン知識(専門知識)はあるけど、プログラムが書けなくてプログラマーに作業を依頼していた状況が、大きく改善されるのではないでしょうか?
またデータセットを設計していた人も、お客さんに説明するために毎回プロット図を作成する必要はなく、プロット図上で話ができるようになります。
このツールのおかげで、これまで以上に開発スピードがあがったり、開発する製品やサービスの品質があがることを期待したいですね。
ここまでご覧いただきありがとうございました。


コメント