こんにちは。
今回はPythonでフルスタックに高速でお手軽にアプリを作るおススメの組み合わせについてご紹介しようと思います。
タイトルの通りですが、最初に結論をまとめておくと、
バックエンド:FastAPI
データベース:SQLite(分析用途ならDuckDB) + SQLModel(可能なら)
フロントエンド:Streamlit
これらの技術スタックについて簡単に解説するとともに、サンプルとしてTodoアプリを構築する方法をご紹介しようと思います。
それではよろしくお願いします。
FastAPIとは?
FastAPIは、PythonでAPIを高速に開発できるWebフレームワークです。

名前の通り「Fast」を意識して作られており、ASGI(非同期サーバーゲートウェイインターフェース)を採用することで非常に高いパフォーマンスを発揮します。
また、型ヒントを活用して自動でドキュメント(OpenAPI/Swagger UI)を生成してくれるため、開発者にとってわかりやすく、フロントエンドや他サービスとの連携もしやすいのが特徴です。
シンプルなコードで動くので、初学者から実務レベルまで幅広く利用されています。
最近の海外の記事を読んだり、LLM周りのGithubなどを見ていても、バックエンドの実装はFastAPIが使われていることが多いように思います。
なので将来的な目線でもFastAPIを習得しておくことは、Python使いとしてはおすすめしたいところです。
SQLite/DuckDBとは?
SQLiteとDuckDBは、どちらも「組み込み型(インメモリ)データベース」と呼ばれる技術で、外部にサーバーを立てる必要がなく、アプリケーション内部で直接データベースを扱うことができます。しかし、それぞれの設計思想は大きく異なります。


SQLite
SQLiteは、OLTP(Online Transaction Processing:オンライン・トランザクション処理)向けのリレーショナルデータベースです。
OLTPとは「アプリの利用者が日常的に発生させる小さな読み書き処理」を素早く正確に扱うための技術で、例としては「ユーザーがタスクを登録・更新・削除する」といった操作が当てはまります。
SQLiteは1つの.dbファイルにすべてのデータを保存し、シンプルで軽量ながらもACIDトランザクションを完全にサポートしています。そのため「小規模アプリ」「モバイルアプリ」「デスクトップアプリ」などで広く利用されています。
DuckDB
DuckDBは、OLAP(Online Analytical Processing:オンライン分析処理)に特化した組み込み型データベースです。
OLAPは「大量のデータを集計・分析する」用途に向いており、数百万行〜数億行規模のデータを高速に処理できます。DuckDBは列指向ストレージを採用しているため、特定のカラムに対する集計や統計処理を効率的に実行できます。さらに、PandasやPolarsとの連携が強力で、分析用Pythonコードの中に違和感なく組み込めるのが大きな強みです。
つまり、
- SQLite = 小規模アプリやトランザクション中心のDB(OLTP向け)
- DuckDB = データ分析やバッチ処理に強いDB(OLAP向け)
という役割分担になります。
今回のような「Todoアプリ」ではSQLiteが適していますが、「タスクデータを分析してレポートを作る」といったシナリオではDuckDBが真価を発揮します。
個人的にはここ数年DuckDB推しなのですが、機械学習やデータサイエンス、そしてLLM開発ではDuckDBが活躍する時代が到来するのではないかと思っています。
なので皆さんもご興味があれば、今からDuckDBを触って慣れておくことをおすすめします。
SQLModelとは?
その前にまず、「ORM(Object Relational Mapper)」について説明します。
アプリ開発ではよく リレーショナルデータベース(RDB) を使いますが、RDBは基本的に SQL という言語で操作します。
一方、アプリ本体はPythonのようなオブジェクト指向言語で書かれています。
ここで問題になるのが「オブジェクト(Pythonのクラスやインスタンス)」と「テーブル(SQLで定義された行と列)」の扱い方の違いです。
たとえば、Pythonで Task クラスを定義しても、そのままでは tasks テーブルに保存することはできません。
この「オブジェクト」と「テーブル」の橋渡しをしてくれるのが ORM です。

ORMを使うと、SQLを直接書かずに Pythonのコード(クラスや関数)でDBを操作できる ようになります。
- SQL文をゴリゴリ書かなくてもよい(コードがシンプルに)
- 型安全・可読性の向上(エディタ補完が効く)
- アプリの拡張・保守が容易になる
といった、コード品質の向上というメリットがあります。
従来のORMとしては、SQLAlchemyというものがありましたが、Pydanticと合わせると、テーブルやクラスを似たような記述で定義するため、コードが冗長になるという課題がありました。
この課題を改善するための新しいライブラリとして、SQLModelが開発されました。

SQLModelは、FastAPIの作者が開発したもので、SQLAlchemyとPydanticをベースにしています。
なので従来のコードの冗長性に対する課題を解決し、かつFastAPIの作者が開発しているためFastAPIとの親和性が高いことが期待できるため、おすすめです。
Streamlitとは?
私のブログではおなじみですが、PythonだけでインタラクティブなWEBアプリを簡単かつ高速に作成することができるフレームワークです。

ボタンや入力フォーム、グラフ表示なども数行で実装可能です。
そのため「プロトタイピング」「データ可視化ダッシュボード」「小規模Webアプリ」に特に強く、バックエンドのFastAPIと組み合わせれば、フルスタック開発をPythonだけで完結できます。
ただし作りとしてはシンプルなもので、細かい設定や変更はできません。
あとはやや処理が重いイメージがあるので、より高速なアプリを組むのには向いていないかもしれません。
本記事では高速かつお手軽を趣旨としているため、この辺は目をつむらせていただきます。
Todoアプリを作る
これらの技術を組み合わせると、シンプルながら拡張性のあるアプリを素早く構築できます。
というわけで早速「Todoアプリ」を作ってみましょう!
ざっくり全体の構成は以下のようなイメージです。
- FastAPI :APIサーバーとしてタスクの登録・更新・削除を担当
- SQLite/DuckDB :タスクデータを保存
- SQLModel :データベースとAPIスキーマの橋渡し
- Streamlit :UIを提供し、ユーザーがブラウザからタスクを操作できる
Githubは以下になります。
最近の私のトレンドとして、Docker環境からuv環境での構築に移行しつつあります。
Pythonの仮想環境はuv一択だと個人的には思っているので、これを機に皆さんもuvをインストールして使ってみてください。

本リポジトリもuvで構築しているため、uvのインストールをお願いします。
解説
全てのコードを解説しきれないので、重要そうな点だけピックアップして解説していきます。
READMEにも記載していますが、まず環境変数として、.envファイルを作成してください。
データベースをSQLiteかDuckDBを選べるようにしてあります。
なぜそのようなことをするかというと、SQLiteかDuckDBによって、SQLModelの記述の仕方が変わるためです。
def id_field(table_name: str, database_url: str = None):
"""SQLiteまたはDuckDB用のIDフィールドを作成する"""
if database_url is None:
database_url = os.getenv("DATABASE_URL", "duckdb:///todos.db")
if database_url.startswith("sqlite://"):
# SQLite用: AUTOINCREMENTを使用
return Field(
default=None, primary_key=True, sa_column_kwargs={"autoincrement": True}
)
else:
# DuckDB用: シーケンスを使用
sequence = sqlalchemy.Sequence(f"{table_name}_id_seq")
return Field(
default=None,
primary_key=True,
sa_column_args=[sequence],
sa_column_kwargs={"server_default": sequence.next_value()},
)これはまぁ端的にSQLの仕様の問題で、SQLiteやMySQL,PostgreなどのRDBSは基本的な仕様が同じなので、同じ書きっぷりが可能なのですが、DuckDBは仕様が異なります。
例えばIDなどの自動インクリメント機能がDuckDBにはないため、sqlalchemy.Sequenceを使って実現しています。
ORMはセッションという単位でデータベースと通信を行っており、これをSQLModelのSessionメソッドとcreate_engineメソッドで管理しています。
from sqlmodel import SQLModel, create_engine, Session, Field
engine = create_engine(DATABASE_URL)
def get_session():
"""データベースセッションを取得する"""
with Session(engine) as session:
yield sessionこのget_sessionを各エンドポイントのDepends(依存注入)に渡してあげればいいという仕組みになっています。
from fastapi import FastAPI, HTTPException, Depends
@app.get("/todos", response_model=List[Todo])
def read_todos(session: Session = Depends(get_session)):
todos = session.exec(select(Todo)).all()
return todos依存注入については少し理解が難しいかもしれないので、参考記事を貼っておきます。

AIとかに例え話を要求すると、レストランのシェフが料理作りに全集中するために材料を集めるスタッフがいて、そのスタッフがDependsだ、みたいな回答をします。
今回でいえばデータベースの通信単位のセッションを管理する機能にDependsをもってきて、各エンドポイントがデータベースの操作を行うという仕組みになっています。
またデータベースのテーブルを定義するクラスも、SQLModelならかなりシンプルになります。
class Todo(SQLModel, table=True, extend_existing=True):
id: Optional[int] = id_field("todo", DATABASE_URL)
title: str = Field(min_length=3, max_length=100)
description: str = Field(min_length=3, max_length=100)
completed: bool = Field(default=False)
priority: int = Field(ge=0, le=6, default=1)
date: Optional[str] = Field(default=None)これがSQLAlchemyとPydanticでORMを構築すると、それぞれでクラスを定義するため、似たようなクラスが二つ並ぶことになります。これが冗長性の課題の件です。
動作画面
では実際に動かしてみましょう。
まずは.envをsqliteに設定して、FastAPIを立ち上げます。
仮想環境の起動方法などについてはGithubのREADMEを参照ください。
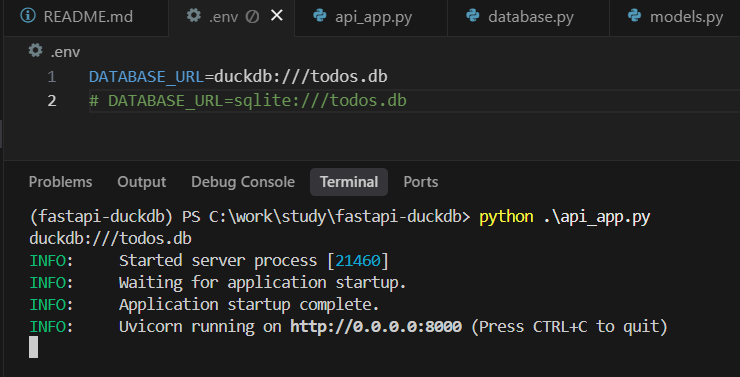
今回はDuckDBを設定します。
FastAPIの起動が完了したら、別のターミナルを起動してStreamlitを起動します。
そうすると以下の画面が起動されるかと思います。
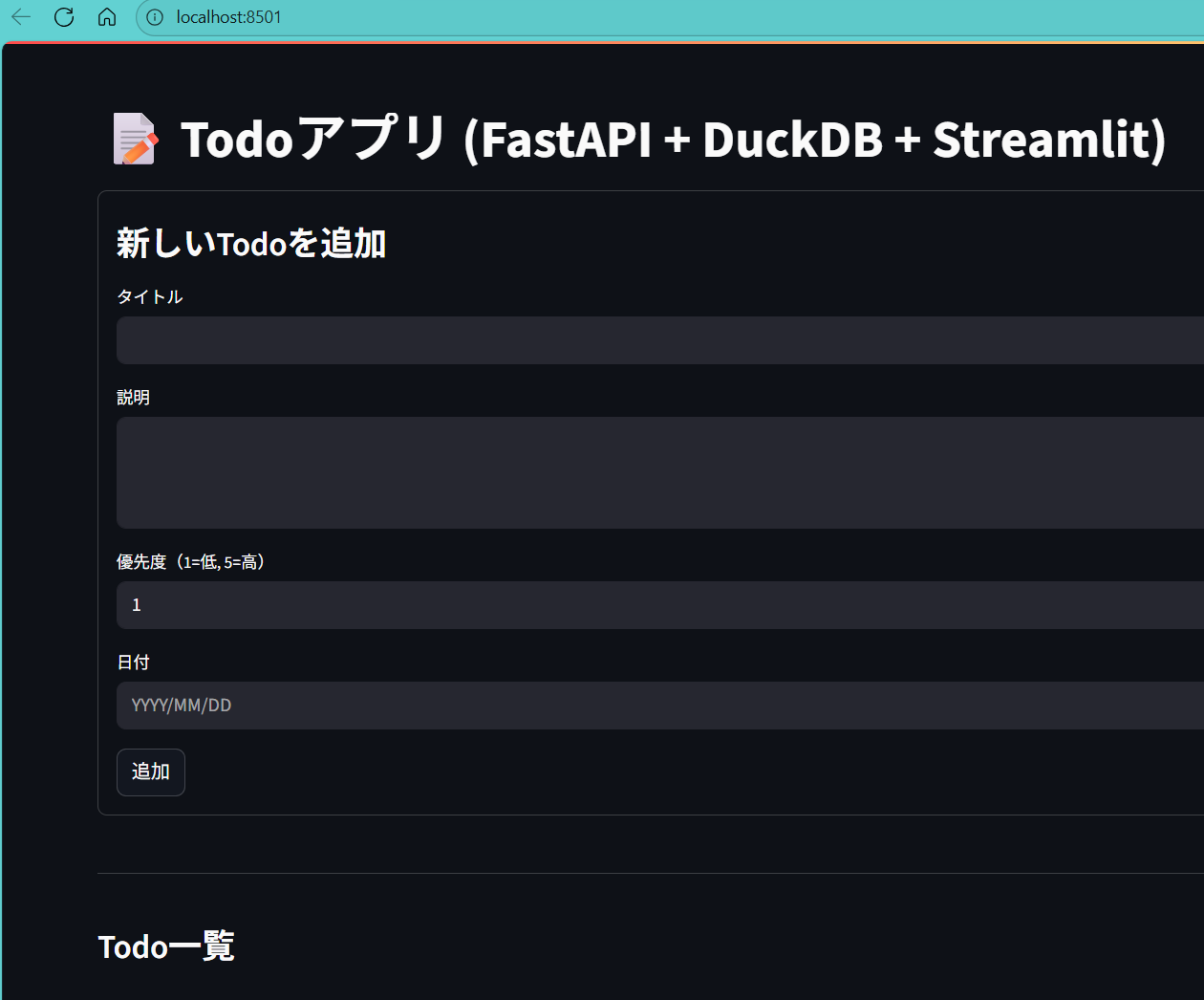
起動されない場合は、http://localhost:8501にアクセスしてみましょう。
では何か適当に記入して、「追加」ボタンを押してみましょう。
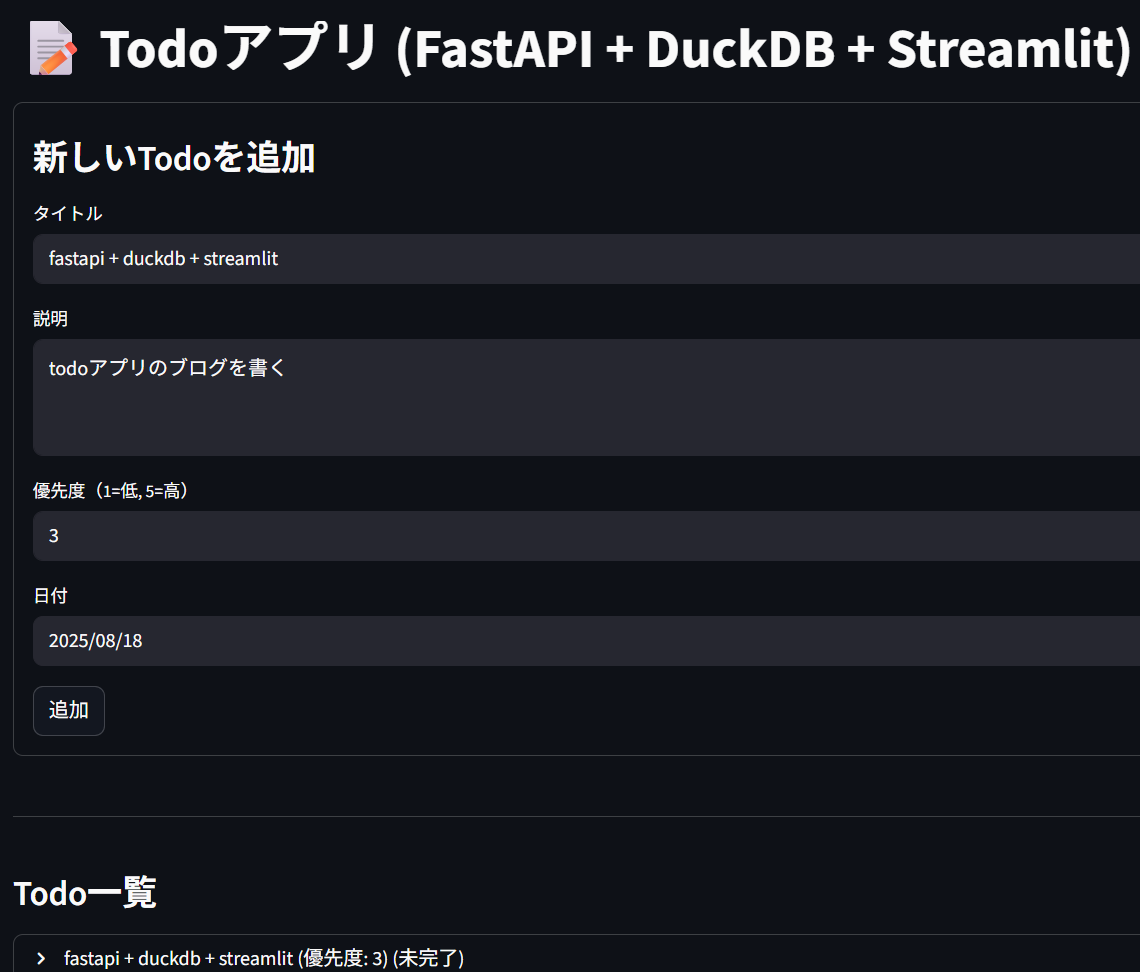
するとTodo一覧に追加されると思います。
Todo一覧を開くと、未完了ステータスを「完了に変更」したり、内容を編集したり、Todoを削除することができます。
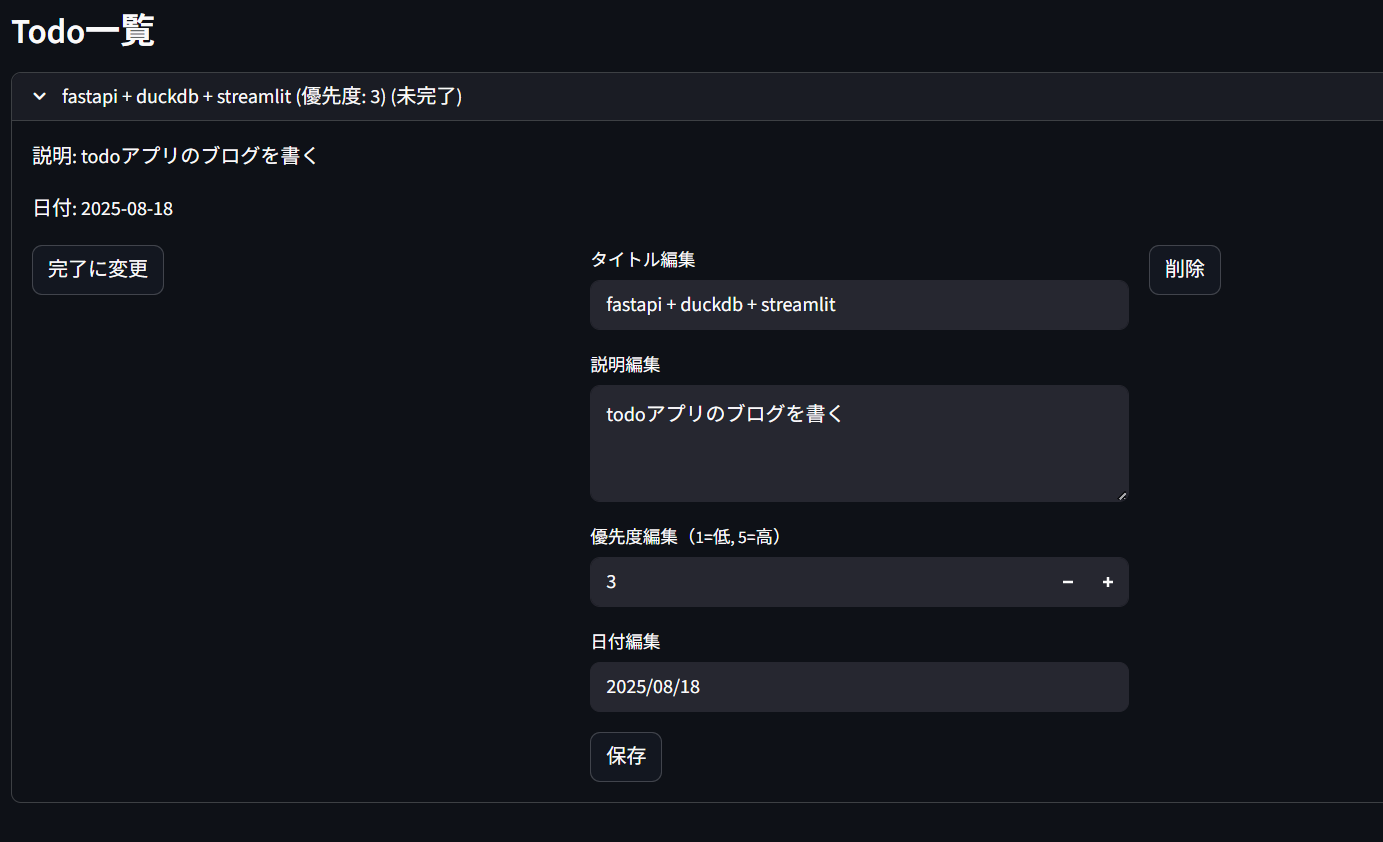
このように基本的なCRUD機能を備えたTodoアプリが簡単にPythonだけで作成することが可能です。
まとめ
今回はPythonでフルスタックに高速かつお手軽に開発する組み合わせとして、FastAPI、SQLite/DuckDB、SQLModel、Streamlitを使ってTodoアプリを作ってみました。
WEBアプリの知識やデータベースの知識を知らなくても、簡単かつ素早く作成することが可能になります。
フルスタックにアプリを開発するためには、どうしてもいろんな開発知識が必要だったり、様々な言語でコードを書く必要があったりするかと思います。
しかし今回ご紹介した組み合わせなら、Pythonだけで簡潔することが可能です。
これで学習コストを大幅に削ることができ、途中で挫折することも減るかと思います。
やはり開発の上達の基本はとにかく素早く一通り自分で簡潔するものを作成することが重要だと思いますので、もし今回の組み合わせが面白かったらぜひ使ってみてください。
ここまでご覧いただきありがとうございました!