こんにちは!
論文を追うとき、よく「このアイデアはどこから出たんだろう?」と思いませんか?
多くの発明は突飛な閃きではなく、現場の“どう削るか・どう足すか”を積み重ねたものです。
今回は「ベースに対する差分」という視点で、画像処理〜深層学習〜LLM と横断的に眺めてみます。
画像処理やAIの知識があると読みやすい内容ですが、できるだけ専門的な用語や知識を使わず解説してみましたので、気楽な読み物としてもご覧いただけます。
それではよろしくお願いします。
画像認識AIの課題と対策
タイトルにある「AIのメモリ不足」というのは、MLエンジニアにとっては永遠の課題かもしれません。
画像データはテキストやテーブルデータと異なり、一つ一つが大きな配列データとなっています。
大量の画像データはあっという間にメモリを消費してしまいます。
画像データをそのままAIの学習や推論に突っ込むことを避けて、
- リサイズする(例:1024×1024の画像を512×512にする)
- 分割して処理した後結合する(例:4分割して、それぞれを処理した後、元の順番で結合する)
という手法が一般的に用いられます。
しかし、リサイズすれば画像は荒くなってしまいますし、ViT(Vision Transformer)のように全体の関係性を考慮するモデルに対しては分割して処理するのはリスクが高いです。
そこで思いついた方法が、「リサイズした画像に対してAIで推論を行い、その出力結果を元のサイズに戻して元画像の差分を元画像に反映させればよいのではないか」という方法です。
図にするとこんな感じ。(ChatGPTに書いてもらいました)
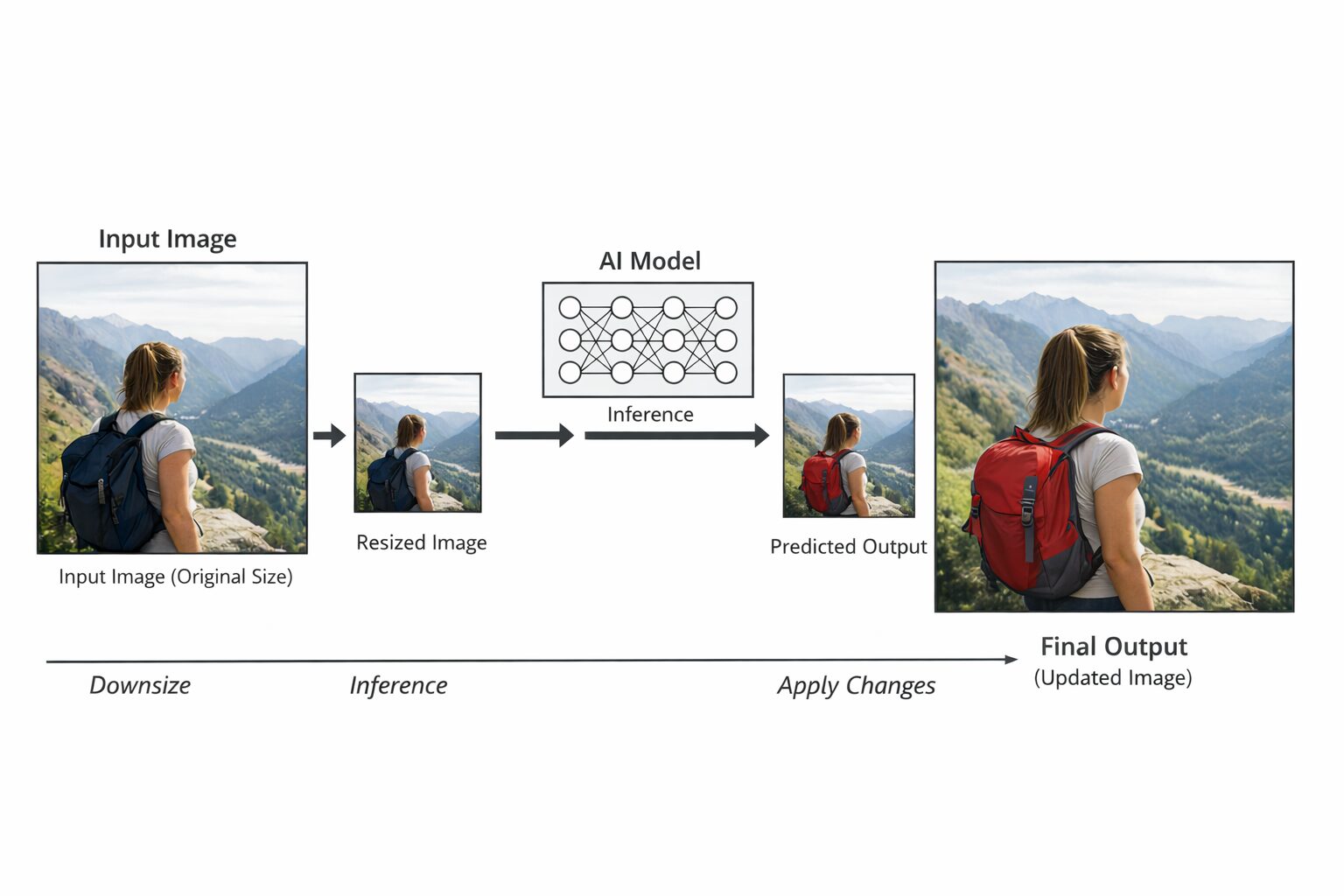
リサイズしたものの推論結果(Predicted Output)は、画像が粗くなってしまうため、そのままでは使えません。
その差分(例ではリュックサックの色)の画素値情報を活用します。
あとはその情報を元画像に転写すればよい、という発想です。
これでAIによるメモリ消費量も減らせるし、処理速度も改善します。
この手法を思いついた時はプチ発明をした気分でしたが、残念ながらこの手法とほぼ同じようなものが既に論文として公開されています。(いわゆる車輪の再発明です)
Fast Guided Filter

Guided Filterとは「ガイド画像」という別の画像(または入力画像自身)を参照しながら、入力画像を平滑化するフィルタです。
OpenCVなどでも実装されています。
Guided Filterに通す前に、入力画像のサイズを縮小(ダウンサンプリング)します。
Guided Filterは局所的な線形モデル q = aI + b を仮定しています。
この係数 a(傾き:エッジの強さ)と b(切片:ベースの輝度)は、空間的に滑らかに変化するという性質があるため、解像度を落としても情報の欠落が少ないのです。
計算された小さな係数マップ a, bを、元のサイズにバイリニア補間などで拡大(アップサンプリング)します。
最後に元画像(ベース)を使い、q = aI + b に当てはめて出力画像を生成します
これは先ほどの私の発想と似ており、縮小した状態で出力することで高速化・軽量化(Fast)を目的としています。
そしてそのままアップサンプリングするのではなく、元画像の精細さを活かしつつ、差分としてどのように戻せばいいかを計算式(線形モデル)で実現しています。
この論文の著者にご注目ください。
Kaiming He
この名前、どこかで見覚えがあるなと思いました。
Kaiming He氏は、ResNetの生みの親です。
Deep Residual Learning for Image Recognition
Deep Residual Learning for Image Recognitionの論文の中でResidual Network、通称ResNetを発表しました。

ResNetは21世紀で最も引用された論文であることでも有名ですが、AIの代表的な発明のひとつだと思います。
ResNetはFast Guided Filterの約半年後に発表されました。
一般的にAIは層が深いほど表現力があがるため、モデルの性能は向上するとされていますが、層が深くなるほど勾配消失など学習が難しくなりやすい傾向を抱えていました。
この課題を解決する手法が残差学習(Residual Learning)です。
入力に対する出力を学習するのではなく、入力 x と出力 H(x) の差分(=残差 F(x))を学習すれば、差分を入力に足しこむだけなので学習がしやすくなるのではという発想です。
論文中にもありますが、数式でいうと以下になります。
具体的に実現する方法として、Shortcut Connection(Skip Connection)です。
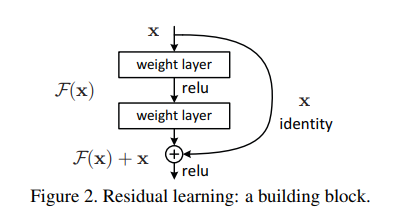
ResNetは高速化や軽量化というよりは学習の安定性のために差分を応用していますが、ベースに対して、後どのぐらいの差分で事足りるのかの発想は共通しているように見えます。
LoRA: Low-Rank Adaptation of Large Language Models
Kaiming He氏が提唱した残差という概念は、今やあらゆる技術に応用されています
ひとつ例をあげるならLoRA: Low-Rank Adaptation of Large Language Modelsが有名でしょうか。

Stable Diffusionなどでその名前を聞いたことがあるかもしれません。
近年LLMなどの大規模なAIモデルをファインチューニングするのは、お金だけでなく時間やエネルギーなどコストが多くかかってしまいます。
そこで効率的なファインチューニングとしてPEFT(Parameter-Efficient Fine Tuning)というものが開発され、その中の手法のひとつがLoRAです。
論文中よりFigure1を引用します。
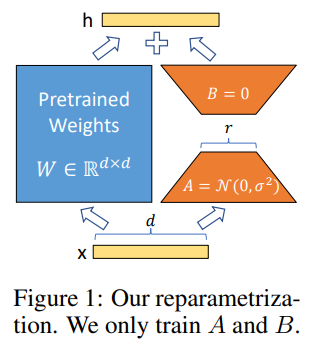
考え方としてはシンプルで、左のPretrained WeightsはLLMなどの大規模モデルです。
こちらはパラメータを更新しません。
更新するのは右側の低ランク行列です。
右側は、左のモデルからファインチューニングした差分の近似を目的としています。
論文中の出力hに関する数式を持ってくるとわかりやすいかと思います。
この数式もどこかで見覚えがありませんか?
要するにモデルからあとどのぐらい足しこめば、ファインチューニング相当になるかを近似する学習手法なのです。
先ほどのベースに対して、後どのぐらいの差分で事足りるのかと同じ発想であることがわかります。
まとめ
AIは突飛な発明ではない
ここまで事例を紹介して、結局何が言いたいのか?
それは、「AIは突飛な発明ではない」ということです。
とある天才が誰も思いつかないような発想から生まれた技術ではなく、実は地道で建設的な発想から生まれたものが多くあるのではないかということです。
今回の画像認識でいえば、メモリの膨大な消費や処理効率の課題をクリアするための建設的な手法があったからこそ、Kaiming He氏はResNetのようなAIを代表する発明ができたのではないかと思ったのです。
基礎の本質を研ぎ澄ます大切さ
自戒も込めて、改めて「基礎技術」って大事だなと感じました。
AIは進歩が速く、キャッチアップするだけでも大変な分野ですが、あまりそっちに翻弄されてもいけないなと感じました。
地に足のついた基礎技術の本質をしっかり身に着け、現場の課題と向き合うことがとても重要です。
温故知新
どうしてもLLMなどのAIツールを追いかけることに注力してしまいがちですが、やはり過去の技術をしっかり理解することも大切です。
技術論文は研究と開発の歴史でもあります。
過去にどういった流れで研究が進んできたのか、どんな課題が今あるのか、その課題に対してどう対処したのか。
これらを理解するなら論文を読むことが大切です。
おわりに
最後に、個人的に伝えたかったことをまとめます。
- 画像処理の古典的な発想が、現代のAI技術の根底を支えている!
- 発明とは突飛な発想からくるものではなく、地道で建設的な現場思考から生まれる!
- あらためて基礎技術の本質と歴史を学ぼう!(論文を読もう!)
最初はメモリ不足を解消したいという切実な悩みから始まった発想が、今や世界を変えるAI技術の根幹を支えている!
もしそうだとしたらワクワクしますし、有名なAI技術者にも親近感がわきませんか?
ここまでご覧いただきありがとうございました!