こんにちは。
みなさん、生成AIを活用していますか?
何番煎じかわかりませんが、faster-whisperとpyannoteを使った文字起こし+話者識別機能を実装してみたので、こちらについてご紹介したいと思います。
これまではAmazon transcribeやAzure VideoIndexerなどの有料ツールを使わないと自動で文字起こしができませんでした。
しかも精度はイマイチで実用に耐えうるようなものではないため、手動での修正が必須でした。
最近では生成AIがあらゆるところで活用されるようになり、OpenAIのWhisperは上記のツールよりも格安かつ高精度です。
今回ご紹介するコードを使えば、これがなんと無料になり、Whisperと同程度な精度の文字起こしができます。
そんな文字起こしの作業を劇的に変化させることができる可能性がありますので、良かったら参考にしてください。
お急ぎの方は「開発環境」のGithubからソースコードを公開してますので、そちらを参照ください。
それではよろしくお願いします。
faster-whisperとは?
faster-whisperとは、本家であるWhisperをCTranslate2というモデルに再実装することで、より軽量化・高速化したモデルのことを指します。
どのぐらい高速かというと、largev2での比較は以下のようです。
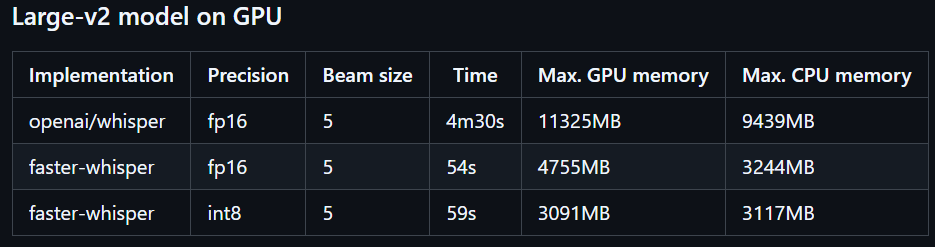
faster-whisperはGPUでもCPUでも動きますし、本記事ではCPUでの動作をメインに紹介します。
なのでGPUがないパソコンをお持ちでも動かすことができますのでご安心ください。
pyannoteとは?
Whisperや文字起こしの精度としては優秀ですが、残念ながら話者識別機能を持ち合わせておりません。
そのため、他の記事でもよく見かけますが、話者識別機能をpyannote(日本語読みは”ピアノート”)というPythonライブラリを用いて実装しています。
本記事でも同様に行います。
準備
ではコードの実装の前に、必要な準備について説明します。
- HuggingFaceのアカウント作成
- HuggingFaceのアクセストークン作成
- pyannoteライブラリの利用規約に関する同意
順番に見ていきましょう。
HuggingFaceのアカウント作成
HuggingFaceとは、AIモデルやデータセットなどを共有するサイトです。
faster-whisperやpyannoteのモデルもここで管理されているため、使用するにはアカウントが必要になります。

右上の「Sign Up」からアカウントを作成しましょう。
HuggingFaceのアクセストークン作成
アカウントを作成してログインしたら、アクセストークンを作成します。
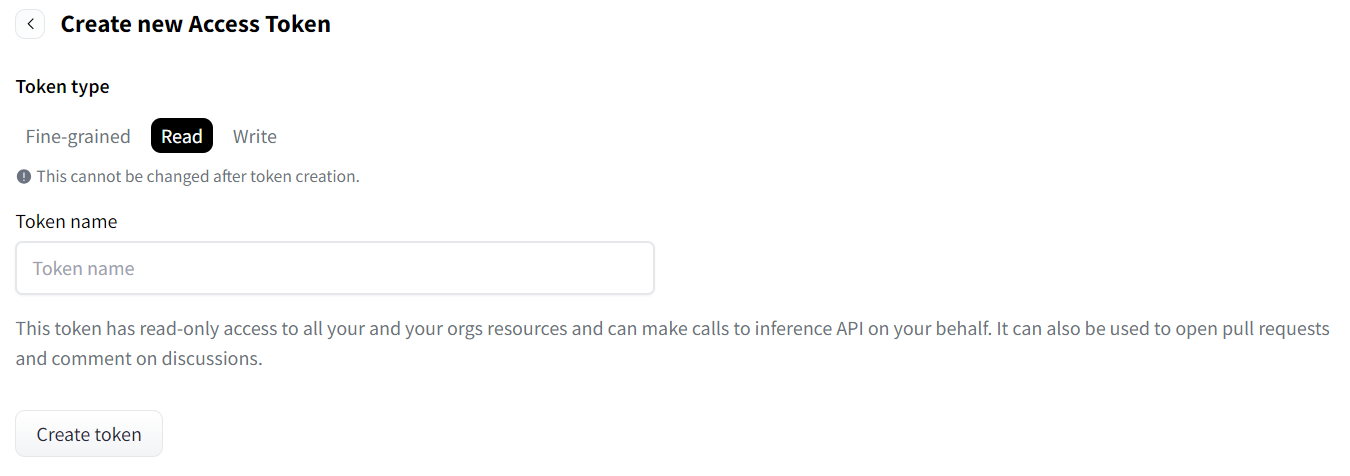
「+ create New Token」ボタンで以下の画面から、「Read」を選択して、読み取り専用のトークンを作成しましょう。
Token nameはなんでもいいです。
「hf-xxxxxxxxx」みたいなトークンが作成されていればOKです。
これをどこかメモ帳にコピーしておきましょう。後で使います。
pyannoteライブラリの利用規約に関する同意
以下の2つのライブラリを使う必要があるので、使うための利用規約に同意しましょう。
適当に記入の上、同意ボタンを押せばOKです。
以上で準備は完了です。
テスト用データ
テスト用の音声データはこちらのサイトから拝借いたします。

こちらのサイトの「G-06」をダウンロードします。
ダウンロードすると、mp3ファイルなのでwavファイルに変換します。
変換にはffmpegを使って変換します。
ffmpegの使い方については、手前味噌ですが以下のブログを参照ください。
WSL2(Linux)なら
sudo apt-get install ffmpegでインストールでき、あとはブログ内の操作方法などを参照ください。
後述のGithub内にもテスト用データはアップロードしておくので、そちらを使っていただいてもかまいません。
開発環境
冒頭でも述べましたが、ソースコード一式については以下のGithubで公開しています。
仮想環境でもコンテナでもどちらでもいいですが、今回はDockerを使って実装します。
WindowsへDockerをインストールするのもとても簡単になりましたよね。
この記事がとてもわかりやすいので、WindowsにDockerをインストールしたことがない方はご参考ください。

Dockerの内容は以下のようにします。
FROM python:3.12-slim
RUN apt-get update
WORKDIR /app
COPY /src /app
RUN pip install -U pip \
&& pip install --no-cache-dir faster-whisper==1.0.2 pyannote-audio==3.3.1
ENV HUGGING_FACE_TOKEN "hf_your_token"pyannoteがpytorchやcudaなど必要なライブラリやフレームワークが多いため、かなりボリュームが大きいです。
なので少しでも軽量化しようということで、ベースイメージは”python3.12″のslim版としています。
環境変数である”HUGGING_FACE_TOKEN”については、準備で作成したHuggingFaceのアクセストークンを入力してください。
これで開発環境としては完了です。
実装
ではコードをサクッと書いていきます。
# instantiate the pipeline
import json
import os
import time
# import faster_whisper
from faster_whisper import WhisperModel
from pyannote.audio import Pipeline
# import torch
import torchaudio
hf_token = os.getenv("HUGGING_FACE_TOKEN")
start_time = time.time()
def concat_whisper_pyannote(segments, diarization, duration):
data = []
for index, _dict in enumerate(segments):
start_time = _dict.start
end_time = _dict.end
text = _dict.text
# WAV再生時間より超えたデータを除外
if start_time > duration:
break
# 時、分、秒、ミリ秒に分割
s_h, s_m, s_s = (
int(start_time // 3600),
int((start_time % 3600) // 60),
int(start_time % 60),
)
e_h, e_m, e_s = (
int(end_time // 3600),
int((end_time % 3600) // 60),
int(end_time % 60),
)
# ミリ秒を計算
s_ms = int((start_time - int(start_time)) * 1000)
e_ms = int((end_time - int(end_time)) * 1000)
# 話者の割り当て
for turn, _, speaker in diarization.itertracks(yield_label=True):
if start_time > turn.end or end_time < turn.start:
continue
else:
current_speaker = speaker
data.append(
{
"id": index + 1,
"start": f"{s_h:02}:{s_m:02}:{s_s:02},{s_ms:03}",
"end": f"{e_h:02}:{e_m:02}:{e_s:02},{e_ms:03}",
"text": text,
"speaker": current_speaker,
}
)
return data
def main(audio_file):
# ============= faster_whisper s ================
model = WhisperModel("large-v3", device="cpu", compute_type="int8")
segments, _ = model.transcribe(audio_file, vad_filter=True)
# ============= faster_whisper e ================
# ============= pyannotte s ================
pipeline = Pipeline.from_pretrained(
"pyannote/speaker-diarization-3.1",
use_auth_token=str(hf_token),
)
# GPUで実行
# pipeline = pipeline.to(torch.device("cuda"))
waveform, sample_rate = torchaudio.load(audio_file)
duration = waveform.shape[1] / sample_rate
diarization = pipeline({"waveform": waveform, "sample_rate": sample_rate})
# ============= pyannotte e ================
results = concat_whisper_pyannote(segments, diarization, duration)
return results
if __name__ == "__main__":
results = main("g_06.wav")
# resultsをjson形式に変換
with open("g_06.json", "w") as f:
json.dump(results, f, ensure_ascii=False)
end_time = time.time()
# minuteで表示
print((end_time - start_time) / 60)
コードについては大きく以下の3点について解説します。
- faster-whisper
- pyannote
- concat_whisper_pyannote
faster-whisper
文字起こし機能の部分です。
cpuで動かす場合は以下のようになります。
model = WhisperModel("large-v3", device="cpu", compute_type="int8")
segments, _ = model.transcribe(audio_file, vad_filter=True)HuggingFace公式をほぼそのままの状態ですね。
vad_filterというのは無音時間を検出してフィルタリングする機能です。
使ってみた感じ、これがあった方が文字起こし精度が良いように見えますので、Trueとしています。(デフォルトはFalse)
またGitを見てもらうとわかりますが、ローカルにあらかじめモデルをダウンロードしておく方法もあります。
こちらについては別記事で紹介予定です。
pyannote
話者識別機能の部分です。
pipeline = Pipeline.from_pretrained(
"pyannote/speaker-diarization-3.1",
use_auth_token=str(hf_token),
)
# GPUで実行
# pipeline = pipeline.to(torch.device("cuda"))
waveform, sample_rate = torchaudio.load(audio_file)
duration = waveform.shape[1] / sample_rate
diarization = pipeline({"waveform": waveform, "sample_rate": sample_rate})こちらもほぼ公式通りです。
コメントアウトしていますが、cudaをインストールしていればGPUで動かすことも可能です。
ただ私もGPUで試したのですが、CPUと比べてほとんど時間が変わりませんでした。
そのポイントがtorchaudio.load(audio_file)だと思います。
これも公式にありますが、パイプラインに実行する前にtensorでメモリにオーディオデータに格納しておくことで高速化が図れる可能性があるようです。

wavデータの再生時間(duration)を取得するために、全データ数をサンプリングレートで割ることで算出しておきます。
こちらもfaster-whisper同様モデルをあらかじめダウンロードしておく方法がありますが、別記事で紹介予定です。
concat_whisper_pyannote
この関数の役割は、名前の通りfaster-whisperの文字起こし結果にpyannoteの話者識別結果を結合することです。
というのも、faster-whisperのタイムスタンプとpyannoteのタイムスタンプにずれが生じるため、このずれを考慮しながら、文字起こし結果と話者識別結果の結合を図る必要があります。
それが「話者割り当て」のコメント部分の条件式です。
start_time > turn.end or end_time < turn.start要するに時間が全く重ならない場合以外なら一致とするような仕様となっております。
この条件式のイメージ図は以下のようになります。

後は文字起こしの出力結果に対して、重なった話者識別結果を結合し、時間をdatetime型で格納するように色々処理しています。
またfaster-whisperの文字起こし結果をみていると、再生時間を超えて、勝手に予測結果を出力していることがあります。
そのような結果は不要なので、先ほど計算したwavファイルの再生時間で切ることにします。
# WAV再生時間より超えたデータを除外
if start_time > duration:
break処理内容の解説は以上となります。
実行結果
これをテスト用データとして用意したg-06.wavで実行した結果は以下です。
[
{
"id": 1,
"start": "00:00:00,000",
"end": "00:00:01,500",
"text": "ワークライフバランス",
"speaker": "SPEAKER_00"
},
{
"id": 2,
"start": "00:00:01,500",
"end": "00:00:07,719",
"text": "仕事と私生活の両面でうまくバランスをとることは、とても大切なことです。",
"speaker": "SPEAKER_00"
},
{
"id": 3,
"start": "00:00:08,839",
"end": "00:00:14,439",
"text": "豊かな個性を持ち、趣味の分野などで個性を発揮するなど視野を広げることで、",
"speaker": "SPEAKER_00"
},
{
"id": 4,
"start": "00:00:15,240",
"end": "00:00:20,359",
"text": "結果的に健全な社員が育ち、仕事の成果につながっていくという考えです。",
"speaker": "SPEAKER_00"
}
]実際の音声を聞いていただくとわかりますが、なんとパーフェクトな精度です!
漢字の間違いも一切なく、わずかな誤字も発生していないことに驚愕です。
これが無料で使える良い時代になりましたな・・。
また実行時間も大体10分程度でしたが、初回はモデルのダウンロードで時間がかかるため、2回目以降は約2分程度で文字起こしと話者識別が可能となります。
まとめ
今回はfaster-whisperとpyannoteを使って文字起こし+話者識別機能を実装してみました。
非常にシンプルなコードでありながら、無料でかつ高精度な文字起こしと話者識別が可能となります。
これは非常に実用に耐えうるものだと思いました。
文字起こしや話者識別でコストを抑えつつ、精度良く実務で使いたいという方の役に立てれば幸いです。
ここまでご覧いただきありがとうございました。