
こんにちは。
先日「DuckDBの魅力解剖」というLT(Lightning Tarkの略)イベントに登壇してきました!

こちらが登壇資料です!

15分という短い時間の中で、DS/ML目線で語ってきました。
LTで語り尽くせなかった補足的な裏話を、この場に書き尽くしたく思います。
ver2025のソースコードの詳細は?
ざっくりと仕組みについては解説したのですが、肝心のソースコードは?というところには触れておりません。
質問もなかったので特に公開していないのですが、もし知りたい方がいたらコッソリここで公開。
ご自由にお使いください。
Windows(WSL)とMacで動作は確認済です。
必要なものは、①Docker②Gemini APIキーです。
詳細はReadmeをご覧ください。
gemini_agent.py が、今回起動したアプリになります。
Geminiに関する記事は以下の記事を参照ください。

GeminiとLangChainのAgentsを使ったアプリなのですが、LangChainのcreate_pandas_dataframe_agentを使っております。

シンプルにPandas(Dataframe)を受け取ったらそれをToolとしてReActで回答するというものです。
コードもすごくシンプルに書けます。
llm = GoogleGenerativeAI(
model="gemini-1.5-flash", temperature=0, api_key=api_key
)
agent = create_pandas_dataframe_agent(
llm,
df,
verbose=True,
allow_dangerous_code=True,
)dfの部分はリストで複数dfを渡すこともできます。
またAgentsなので、どういう思考をしたかはコンソールに出力してくれます。
今回はStreamlitアプリに表示させたかったので、StringIOを使いました。
# ログキャプチャ用のStringIOを設定
log_stream = StringIO()
sys.stdout = log_stream # 標準出力をStringIOにリダイレクト
(中略)
# ログを取得して表示
st.sidebar.subheader("Agentの思考Logs")
logs = log_stream.getvalue()
st.sidebar.text_area("Logs", logs, height=300)こうすることで、コンソール出力をStreamlit出力にできます。
PygWalkerも実は進化していた話
gemini_agent.pyの中に、PygWalkerもあるのですが、ver2023から仕様が変わっていました。
2025のライブラリで早くなったよーってしゃべってた件のソースコードはこちら。

use_kernel_calcがなくなり、kernel_computationに代わりました。
kernel_computationをTrueにすると、DuckDBによるSQLエンジンでのデータ操作が実施され、大容量のデータも高速にあつかえる、らしいのです。
@st.cache_resource
def get_pyg_renderer(df: pd.DataFrame) -> str:
renderer = StreamlitRenderer(df, kernel_computation=True)
return rendererそして現在の新しいコードだとついに・・・。
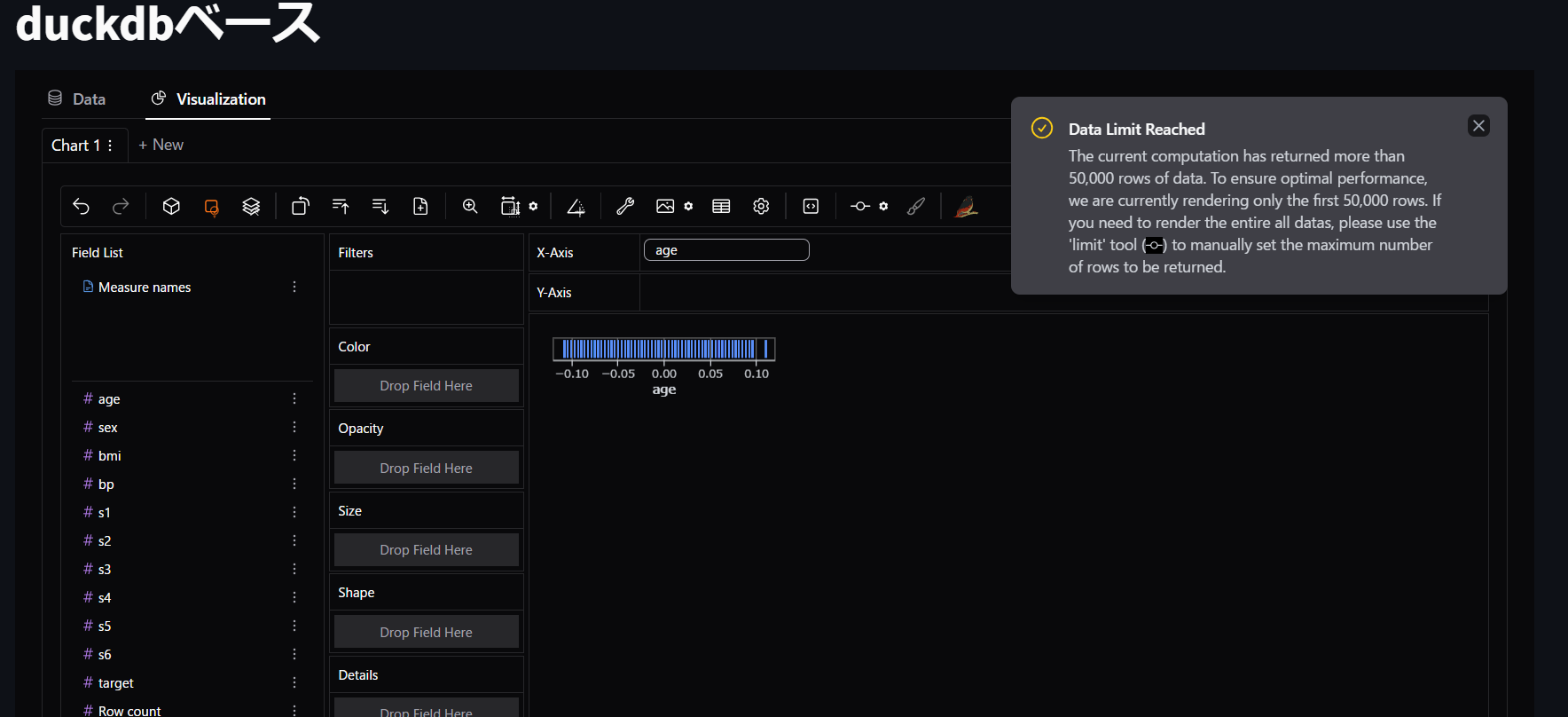
読み込めました!ver2023ではageを入れるとアプリが動かなくなってましたが、ver2025は読み込めるんです!
さらに・・・
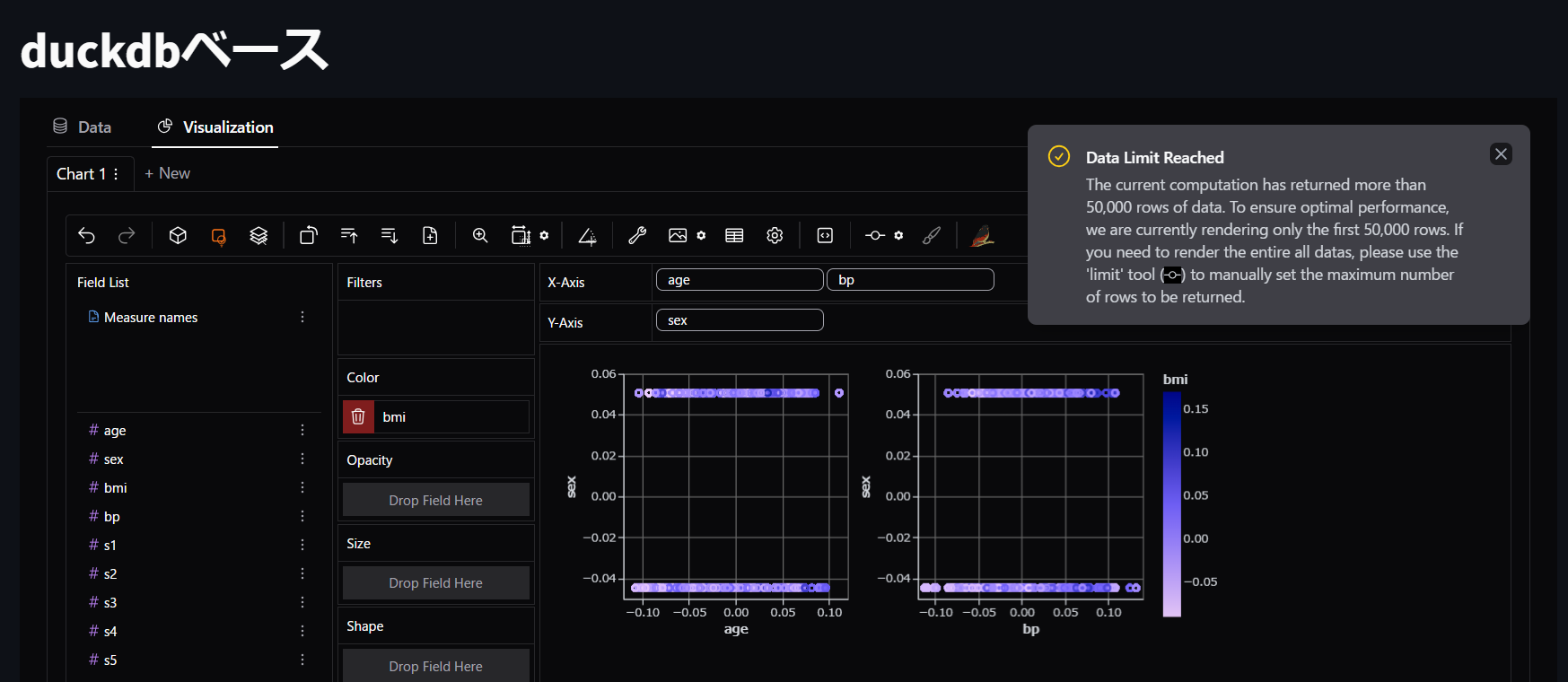
ここまでいけるんですね!1年越しにやりたかったことがついにできるようになりました!(泣)
50000行を超えるものは、自動的に50000行までになって、それ以降も表示したいなら設定で制限を決められる仕様になったようですね。
まぁ50000行も一度に表示して分析することはあまりないし、そこからみたいところを適宜拡大していくのが普通だと思うので、この仕様はとても実務的で理にかなっていると思います。
DuckDBのLTなので、本筋ではないため語れませんでしたが、この感動はここでだけ共有しておきます。
LlamaIndex(RAG)とDuckDBがどう関連していたのか
ここも端折ってしまったところですね。
一番言いたかったことは、「Dataframeとの相性の良さのおかげで、VectorDBに登録した情報の抽出・加工・可視化のしやすさが他DBよりも優位である」ということです。
それはLTで申し上げられたので良かったです。
で、その前段階ですよね。VectorDBに登録するまで。
LLMのRAGにDuckDBがどう関連しているのか、これについては深く語ると1本記事が書けてしまうため、VectorDBに登録するまでについてだけ語ります。
RAGのためのドキュメントをDuckDBにVectorDBとして登録するコードは以下です。
documents = SimpleDirectoryReader("data/paul_graham/").load_data()
vector_store = DuckDBVectorStore()
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex.from_documents(
documents, storage_context=storage_context
)DuckDBVectorStore()に何も引数を与えないとインメモリ上での保存となるため、処理が終われば削除されます。
永続的にDBとして残したい場合は以下のようにします。
vector_store = DuckDBVectorStore("pg.duckdb", persist_dir="./persist/")こうすることで、DuckDBとして保存できるので、毎回最初から作らず、再度読み込むことでRAGのVectorDBを更新することができるのです。
そこで、今VectorDBがどうなっているかを管理する必要が出てくる、というわけで話がつながります。
まとめ
というわけで感想&裏話でした!
いやーそれにしてもとてもいい勉強になったので、また何かの機会で登壇したいですね。
それまでにいい技術ネタを磨いておかねば。。
最後に今後の展望を述べて締めたいのですが、やはりLLM開発でのDuckDB活用には取り組みたいですね!
特にDataframeを駆使してドキュメント管理の部分だったり、複雑なRAGやAgentsシステムを構築してDuckDBでデータを管理する、みたいな実装をどんどんやっていきたいです。
あとは純粋にデータ基盤にDuckDBを導入していくよう、自分が関わる開発現場の皆様への布教活動(?)なんかも推し進められたらいいなって思います!
というわけで、LTをご覧いただいた皆様と、この記事を最後まで読んでいただいた皆様に感謝!
ありがとうございました!

