
こんにちは。
今回は最近リリースされたHermes DesktopにOllamaが連携したようなので、これについてご紹介します。

これまで紹介したHermes AgentはコマンドプロンプトなどのCLI上での操作でした。
エンジニアの方は割となじみがあるかもしれませんが、普段コードを書かない人からすると、どうしてもとっつきにくいところがあったかと思います。
また細かい設定は.hermsフォルダ内のMarkdownやJSONを参照しないといけません。
この辺結構面倒だなと私も感じていたのですが、今回のDesktop版リリースとOllamaの連携はまさに朗報です!
かなり操作性が良くなりました!
という訳で今回はその良くなったと感じた点や特に私が注目しているルーティング機能についてご紹介しようと思います。
OllamaでのHermes Agentのインストールが完了した状態を前提に話を進めます。

まだ設定が終わっていない方はこちらの記事を参照の上、ご覧いただくと良いと思います。
それではよろしくお願いします。
Hermes Desktopのインストール
以下のリンクから、お使いのPCにあったアプリのダウンロードします。

私はMac環境で進めますが、Windows(WSL)やLinuxでも特に目立った差分はなさそうです。
アプリをダウンロードしたらインストールします。
インストールの際、特に設定や入力はありません。
インストールが完了したらollamaと紐づけて起動するため、以下のコマンドをコマンドプロンプト等で入力して見ましょう。
ollama launch hermes-desktopするとOllamaでインストール済のモデル一覧から選択できると思うので、好きなものを選んでください。
最近Gemma4の12Bがリリースされたので、こちらも一般的なノートPCでメモリが16GBぐらいあれば動くのでおすすめです。

以下のような画面が立ち上がればHermes Desktopの準備はOKです。

サイドバーに注目してください。
今までの会話(Session)履歴が見れるようになったり、スキルやツール一覧の確認や有効か無効かを切り替えることができます。
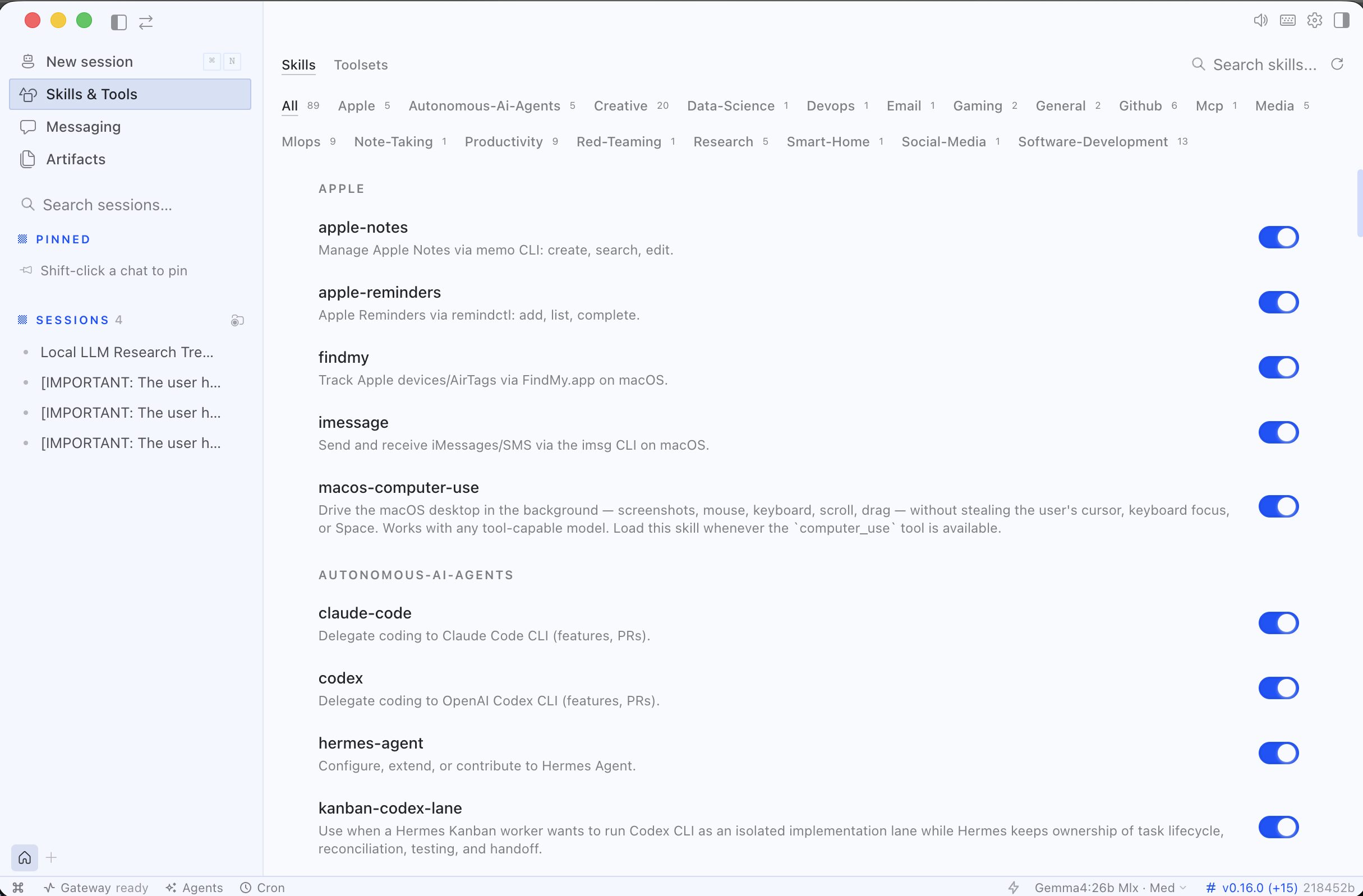
今までのCLI画面の状態では有効無効の切替はできませんでしたし、わざわざ.hermesフォルダ内のskillsフォルダを確認しにいく必要がありました。
アプリ上で設定や履歴の管理がとても容易になったと感じます。
ではいくつかHermes Desktopの設定方法を見ていきましょう。
Hermes Desktopの設定
外観を変えよう
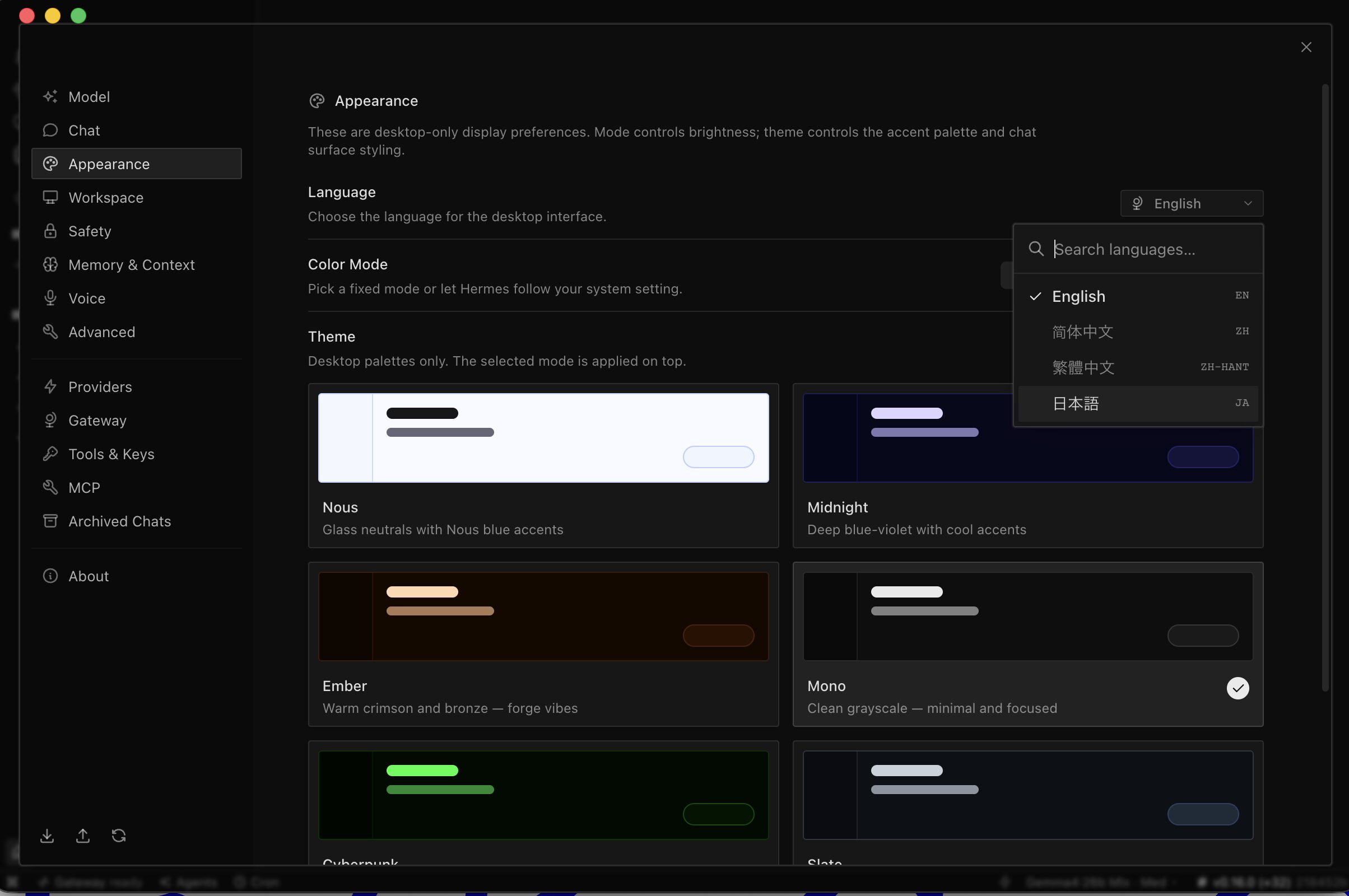
アプリの右上に小さく歯車アイコンがあるのでクリックします。
「Appearance」というのがあるので、これをクリックすると「Language」があるので、日本語を選択しましょう。
Color ModeやThemeも好きなものを選んでください。
チャットの性格やタイムゾーンを変更しよう
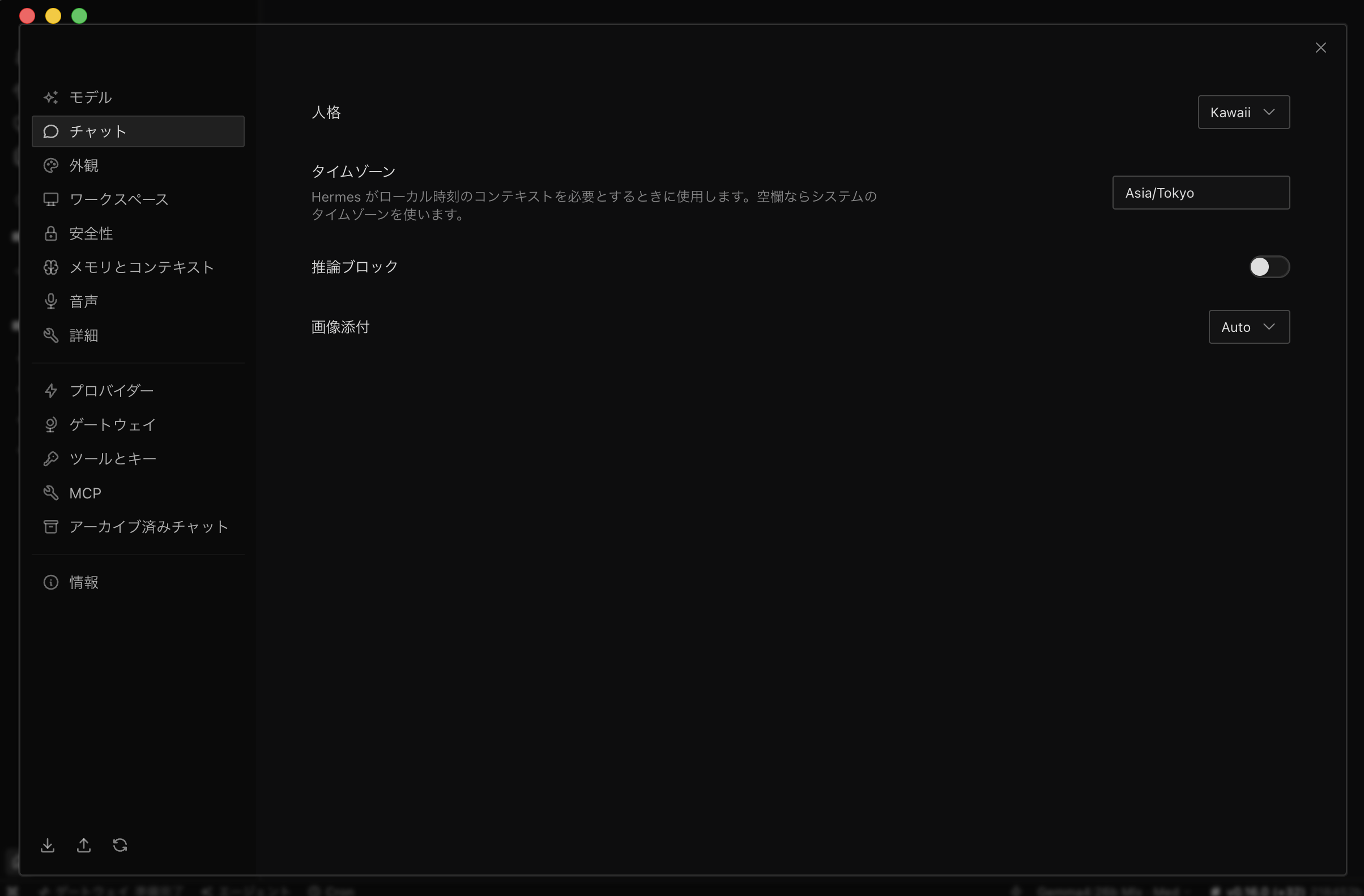
チャット時の性格も簡単に変えられます。
「チャット」をクリックすると、「人物」があります。
デフォルトは「kawaii(なぜか日本語!)」となっていますが、これも好きなタイプを選択してください。
タイムゾーンも設定でき、IANAタイムゾーン文字列を入力します。
東京は「Asia/Tokyo」なので、これを記入しましょう。
以前私の記事では、このタイムゾーンをチャットにて指示しましたが、ちゃんと記録されているのか、これで管理できそうです。
モデルを複数設定しよう(ルーティング)
さて本記事の本題です。
Hermes Agentはルーティングができますが、Hermes Desktopを使うとより簡単に設定できます。
ルーティングというのはタスクに応じて使用するモデルを切り替える手法のことです。
基本全てのタスクでGemma4を使ってもいいのですが、それだと時間がかかったり、タスクによっては期待する回答の精度が得られない場合もあります。
今後のAIエージェント設計においては、最適なタスクに最適なモデルを割り当てる効率の良い設計が重要になってくると思います。
今回はHermes Desktopでその片鱗を少しでも体験してもらえればと思います。
「モデル」をクリックすると以下のような画面で管理できます。
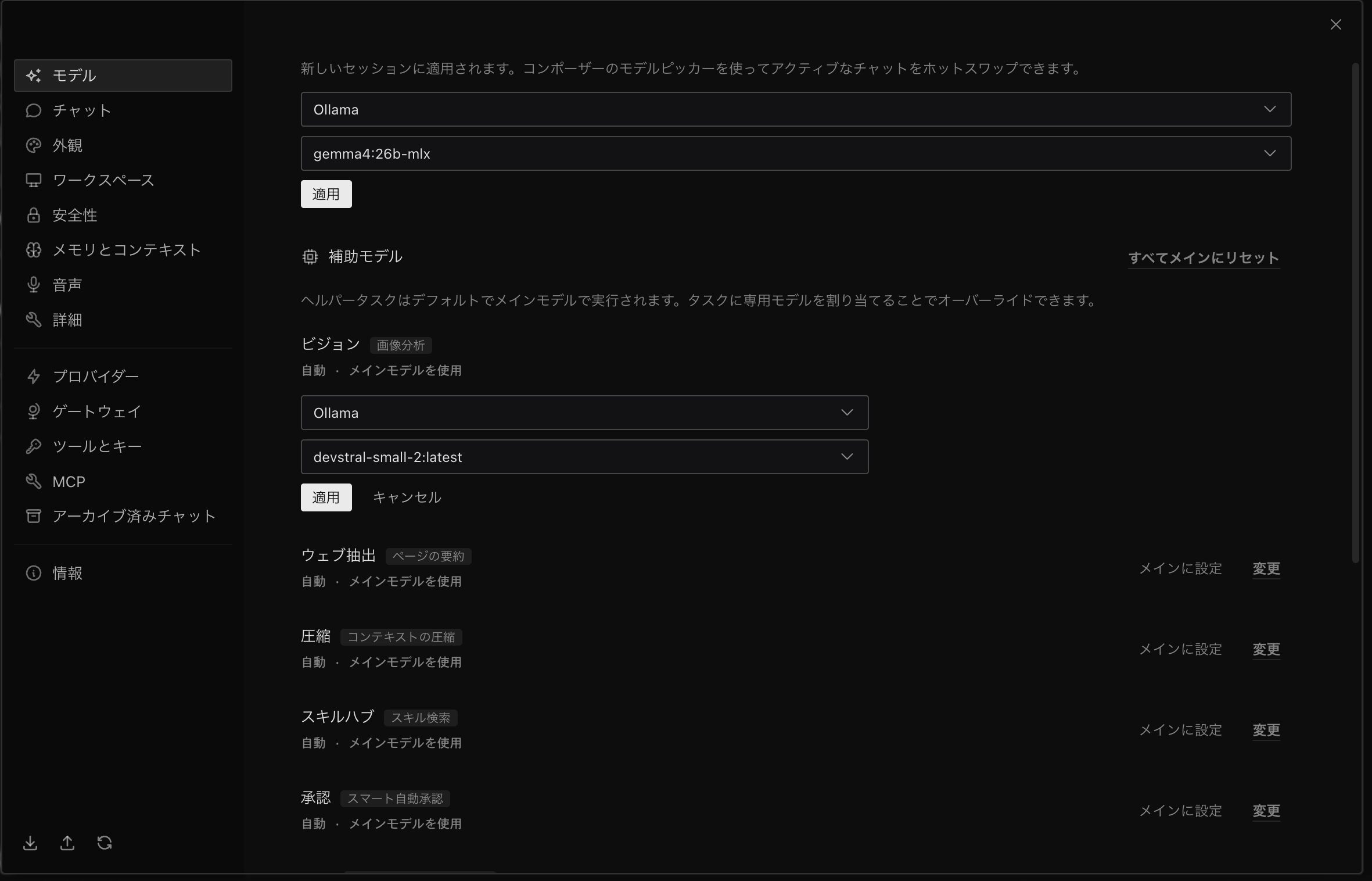
Ollamaで起動することで、メインモデルは既に設定されていますが、補助モデルと書いてある部分がルーティング対象になります。
例えばビジョン(画像分析)ができるモデルはGemma4よりもっと軽量で精度の良いモデルがあります。
OllamaではMistral社のDevstralが個人的には性能が良いと感じているのですが、これに割り当てることが可能です。
このようにHermes Desktopを使うと、メインで思考をするのはGemma4、画像分析をするのはDevstralといったようにOllama内のローカルモデルを自由に割り当てることが容易になります。
CLIの時でも設定ファイルをいじれば可能だったのですが、なかなか面倒でした。
Desktop化によって記事として紹介しやすくなったのもうれしいポイントです。
ルーティングの効果を実感する
ではルーティングは本当に効果があるのかどうか簡単な実験をしましょう。
GemmaシリーズはGemma 3の頃から、実は画像認識が苦手ではないかと日々検証している中で感じています。
ここでは実験として2枚のグラスの写真を用意します。(画像はnano bananaで作成)
1枚目は割れて中身がこぼれたグラス、2枚目は割れていないグラスの画像です。
これを時系列順に並べてもらいましょう。
まずはルーティングとして画像分析をDevstralに設定した場合の結果は以下です。
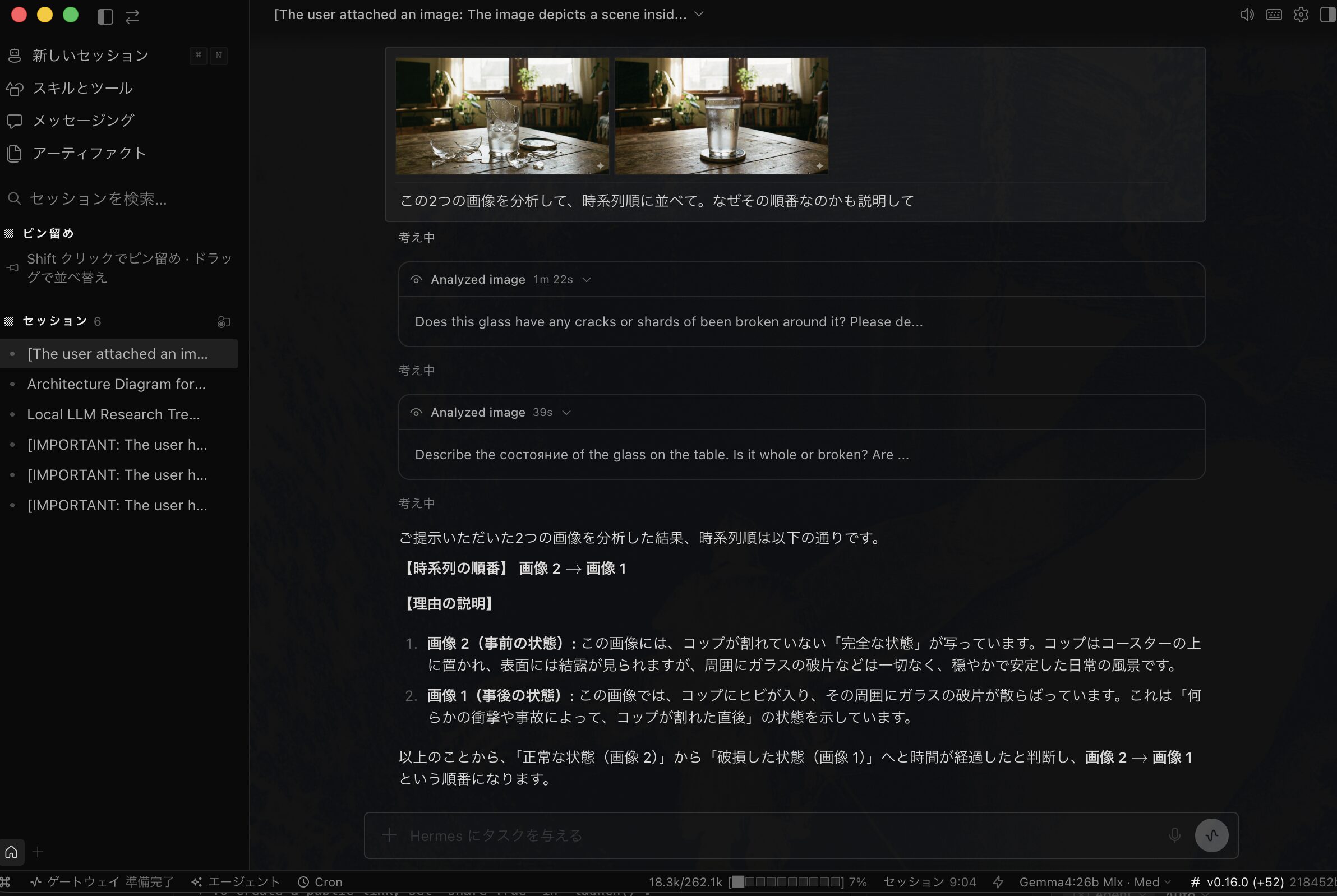
問題なく分析できています。
画像が割れてない方が先で、割れた方が後になる並びで正解です。
理由も正しく説明できています。
ではルーティングせず、Gemma4にすべて回答させるとどうなるでしょう。
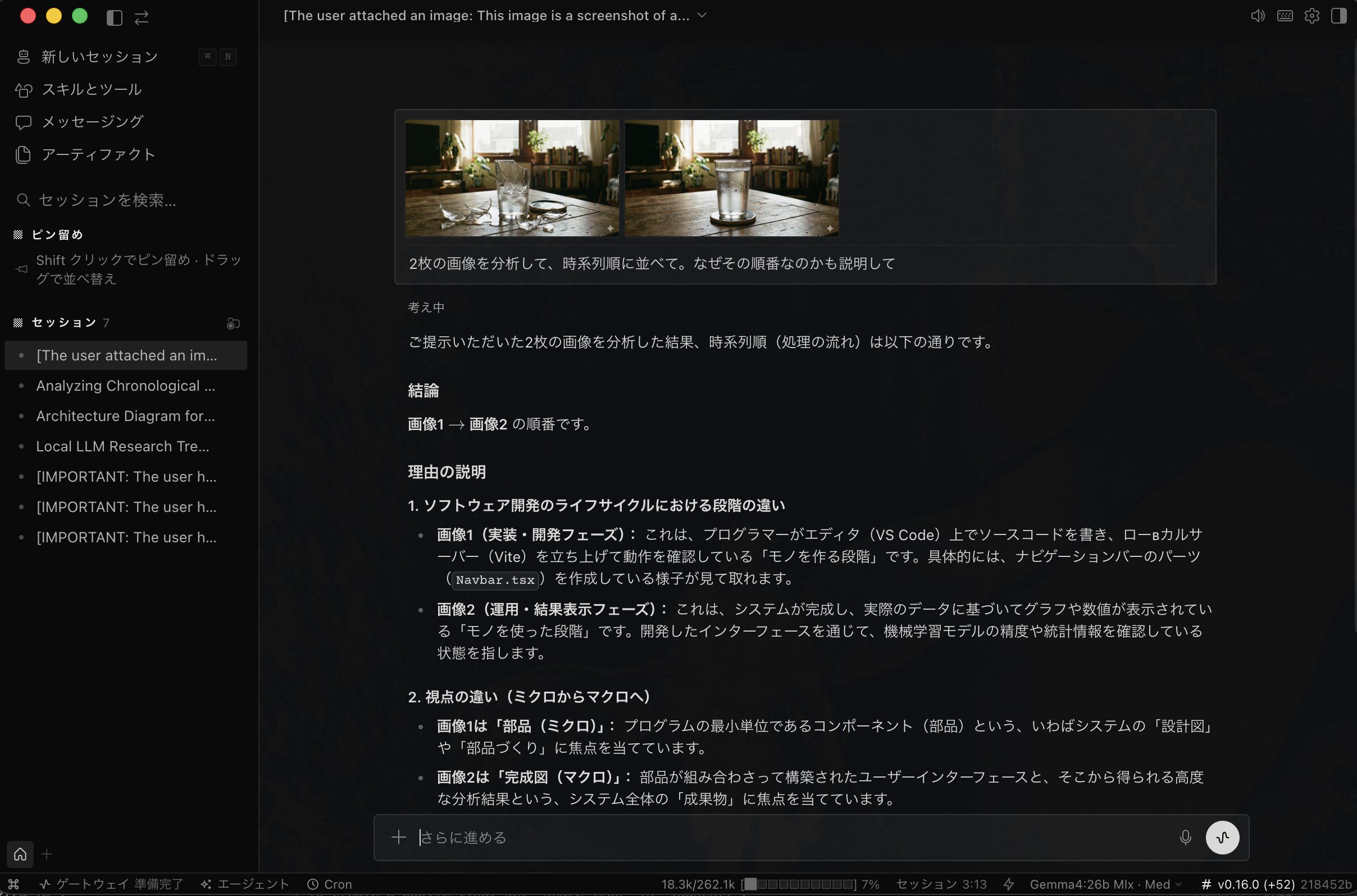

ちなみに3回ずつルーティングありなしでそれぞれ実験しましたが、3回とも似たような結果です。
ルーティングありは3回とも正解し、ルーティングなしは意味不明な回答で不正解です。
このようにGemma4では達成できない苦手なことも、ルーティングすることで達成できるようになります。
また処理速度についても、Gemma4単体で実施した時が2分30秒ぐらいかかっていたのが、大体2分程度で完了したため、処理速度も向上しています。
では同じくMistral社のさらに軽量なministral-3を使うとどうなるでしょうか?
こちらも軽量ながら、画像認識に優れたモデルだと感じているものです。
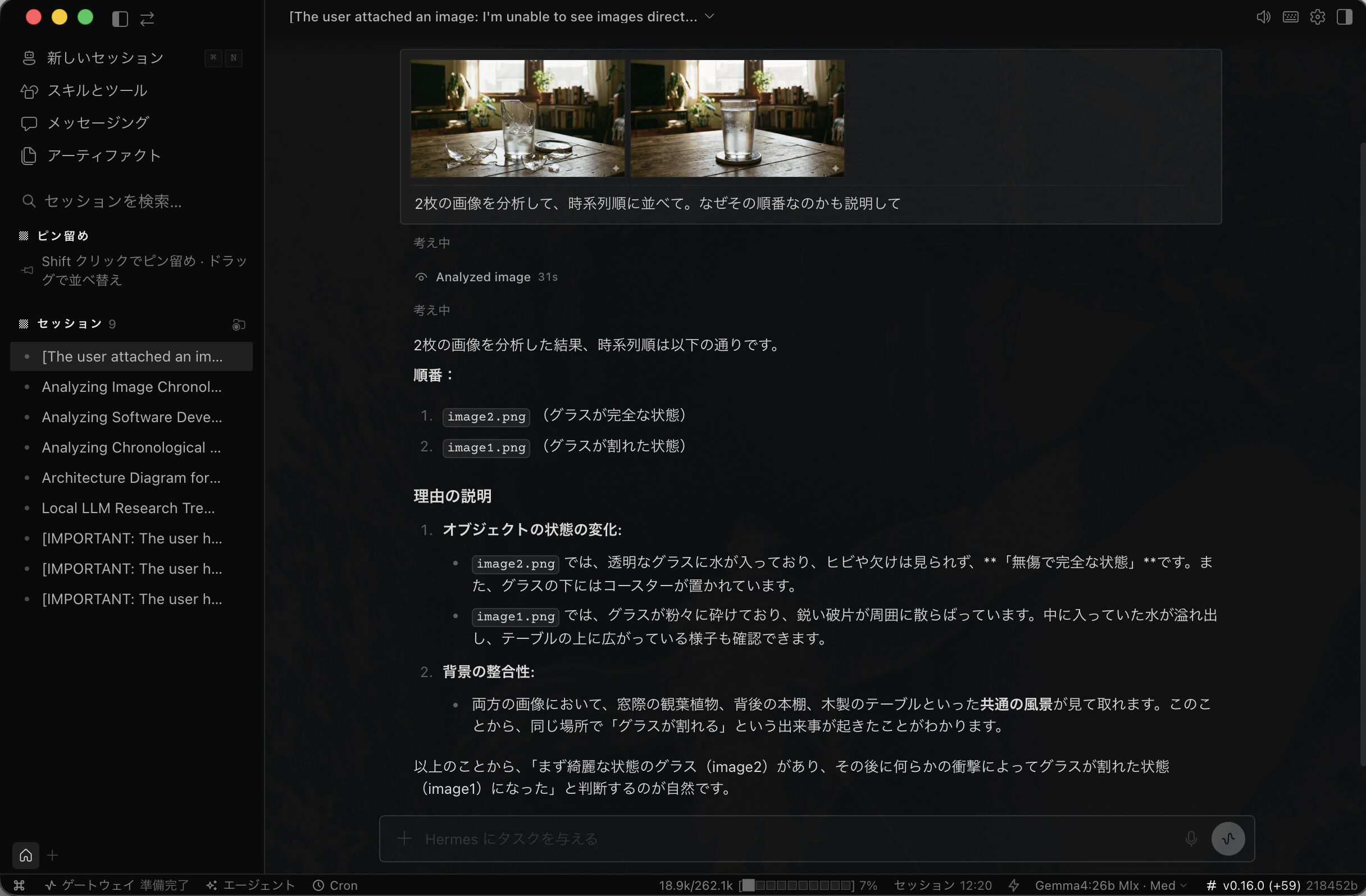
ある意味Devstralよりも良さそうな回答しますね。笑
ministral-3でも成功しました。
処理時間も1分ちょっとぐらいだったので、さらに速いです。
正直このタスクならば、そもそもGemma4を介さなくても良いのですが、現場で使うとなるとその辺の判断や切替をAIエージェントにゆだねることになるかと思います。
全部Gemma4のような汎用モデルにタスクをこなさせるのではなく、ルーティングを上手く活用することでより良い成果を効率よく達成することができるのではないかと思います。
まとめ
今回はHermes DesktopをOllamaと組み合わせた使い方、特にローカルLLMをルーティングする方法についてご紹介しました。
Hermes Agentは今注目集めているAIエージェントツールであり、これを人がコントロールしたり管理することが重要です。
Hermes Desktopはその目的を達成するツールとして有効であり、Ollamaと組み合わせるとさらに効率よくローカルLLMを組み合わせるルーティングも簡単に実装することが可能となります。
AIエージェント開発も更なるステップに進もうとしています。
より小型で効率の良い特化型のAIを複数稼働させることが、これほど簡単に実装できる時代になってきました。
ご興味ありましたら、Hermes Desktop + Ollamaでルーティングを試してみてください。
ここまでご覧いただきありがとうございました!

